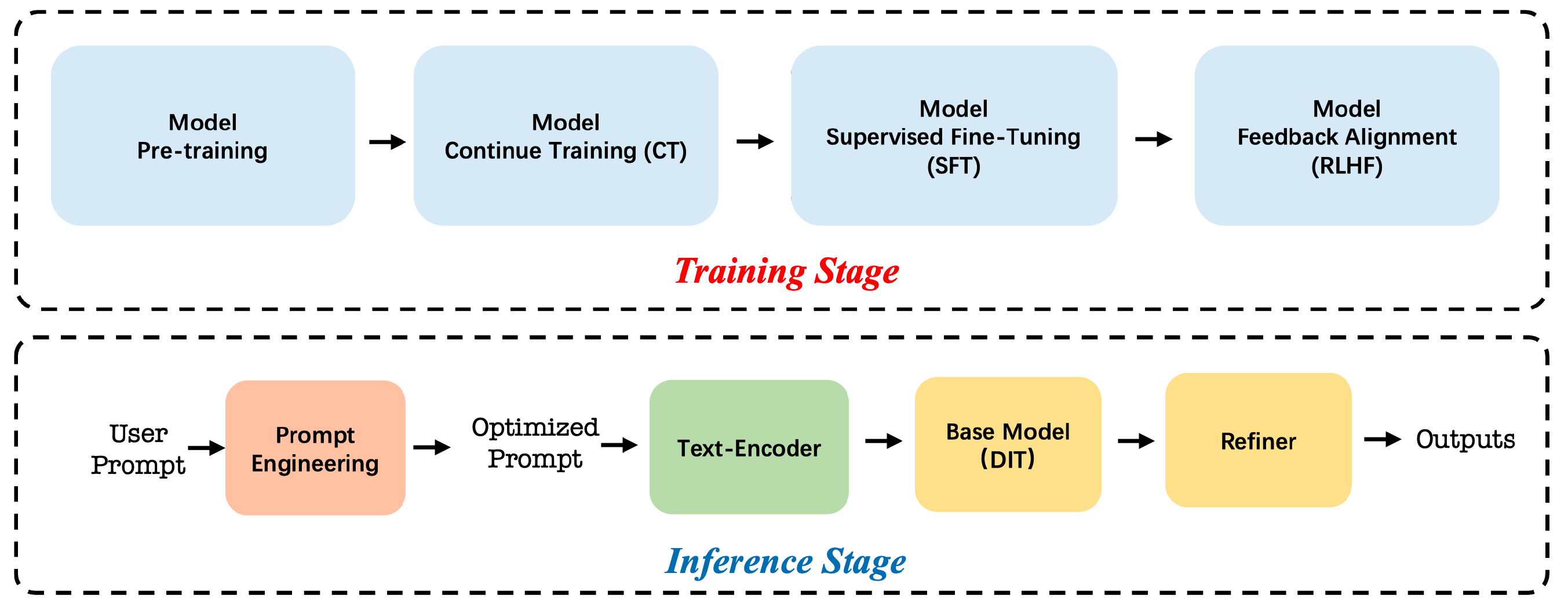
Inference Beat Pretraining
noise-unconditional model
Flow Matching Guide and Code

Unified Perspective
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-03-10 Inference Beat Pretraining |
Ideas in Inference-time Scaling can Benefit Generative Pre-training Algorithms (arXiv 2025) | Analyze pre-training algorithm design from a inference-first perspective, and scaling inference from a unified perspective of scaling sequence length & refinement steps. |
| 2025-02-18 noise-unconditional model |
Is Noise Conditioning Necessary for Denoising Generative Models? (arXiv 2025) | Theoretical and empirical analysis on noise-unconditional denoising diffusion models without a timestep input for image generation. |
| 2024-12-09 Flow Matching Guide and Code |
Flow Matching Guide and Code (arXiv 2024)
|
Comprehensive and self-contained review of the flow matching algorithm, covering its mathmatical foundations, design choices, extensions, and code implementations. |
| 2022-08-25 Unified Perspective |
Understanding Diffusion Models: A Unified Perspective (arXiv 2022) | Introduction to VAE, DDPM, score-based generative model, guidance from a unified generative perspective. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-04-15 SimpleAR |
SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL (arXiv 2025)

|
A vanilla, open-sourced AR model (0.5B) for 1K text-to-image generation, trained by pre-training, SFT, RL (GRPO), acceleration (KV cache, vLLM serving, speculative jacobi decoding). |
| 2025-04-15 Seedream 3.0 |
Seedream 3.0 Technical Report (arXiv 2025) | ByteDance Sead Vision Team's text-to-image generation model (MMDiT structure), improve Seedream 2.0 by defect-aware training, representation alignment, larger reward model, etc. |
| 2025-04-11 Seaweed-7B |
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model (arXiv 2025) | ByteDance Seaweed Team's text-to-video & image-to-video generation model (7B) with DiT structure, trained (multi-task learning) on O(100M) video clips using 665K H100 GPU hours. |
| 2025-03-26 Wan |
Wan: Open and Advanced Large-Scale Video Generative Models (arXiv 2025)

|
Alibaba Tongyi Wanxiang's open-sourced model (14B) for text-to-video & image-to-video generation, using 8x8x4 VAE, DiT structure, etc. |
| 2025-03-14 Step-Video-TI2V |
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model (arXiv 2025)

|
StepFun's open-sourced model (30B) for image-to-video generation, trained upon Step-Video-T2V, by using channel concat of image condition and timestep-combined motion condition. |
| 2025-03-10 Seedream2.0 |
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model (arXiv 2025) | ByteDance Sead Vision Team 's foundation model for image genertion with native Chinese-English bilingual capability, where some techniques such as scaled RoPE, SFT, RLHF are employed. |
| 2025-02-14 Step-Video-T2V |
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model (arXiv 2025)

|
StepFun's open-sourced model (30B) for text-to-video generation, using DiT structure & RoPE-3D & QK-Norm & 16x16x8 VAE & two bilingual text encoders & DPO. |
| 2024-12-05 Infinity |
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis (arXiv 2024)

|
It improves VAR by applying bitwise modeling that makes vocabulary "infinity" to open up new posibilities of discrete text-to-image generation with next-scale prediction paradigm. |
| 2024-12-03 HunyuanVideo |
HunyuanVideo: A Systematic Framework For Large Video Generative Models (arXiv 2024)

|
Tencent (Hunyuan Team)'s open-sourced video generation model (13B) using diffusion transformer and conducting fine-grained data curation, captioning, and training scaling. |
| 2024-10-17 MovieGen |
Movie Gen: A Cast of Media Foundation Models (arXiv 2024) | A diffusion transformer-based model (30B) for 16s / 1080p / 16 fps video and synchronized audio generation. |
| 2024-10-17 Fluid |
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens (ICLR 2025) | It shows auto-regressive models with continuous tokens beat discrete tokens counterpart, and some interesting empirical observations during scaling progress. |
| 2024-07-16 DiT-MoE |
Scaling Diffusion Transformers to 16 Billion Parameters (arXiv 2024)

|
A diffusion transformer (16B) with MoE that inserts experts into DiT blocks for image generation. |
| 2024-06-10 LlamaGen |
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation (arXiv 2024)

|
Show that applying "next-token prediction" to vanilla autoregressive models achieves good class-conditional & text-conditional image generation performance. |
| 2024-04-03 VAR |
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction (NeurIPS 2024 Best Paper)

|
Employ next-scale prediction to make auto-regressive models surpass diffusion transformers for image generation on image quality, inference speed, data efficiency, scalability. |
| 2023-07-04 SDXL |
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis (ICLR 2024)

|
Employ three times larger UNet backbone of SD, use resolution & crop coordinates & bucketing information as resolution condition for training, employ a refinement model. |
| 2022-12-19 DiT (notes in jupyter) |
Scalable Diffusion Models with Transformers (ICCV 2023)

|
Replace U-Net by transformer for scalable image generation, the timestep and prompt are injected by adaLN-Zero structure. |
| 2022-10-06 Flow Matching |
Flow Matching for Generative Modeling (ICLR 2023)
|
A type of generative models built on continuous normalizing flows by learning a time-dependent vector field that transports data from the source distribution to the target distribution. |
| 2022-05-29 CogVideo |
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers (ICLR 2023)

|
An open-sourced transformer-based video generation model (9B) that auto-regressively generates frame sequences and then performs auto-regressive frame interpolatation. |
| 2021-12-20 LDM |
High-Resolution Image Synthesis with Latent Diffusion Models (CVPR 2022)

|
Efficient high-quality image generation by applying diffusion and denoising processes in the VAE latent space. |
| 2021-12-08
CFG (notes in jupyter) |
Classifier-Free Diffusion Guidance (NeurIPS workshop 2021) | Image generation with classifier-free condition guidance by jointly training a conditional model and an unconditional model. |
| 2020-10-06
DDIM (notes in jupyter) |
Denoising Diffusion Implicit Models (ICLR 2021)

|
Accelerate sampling of diffusion models by introducing a non-Markovian, deterministic process that achieves high-quality results with fewer steps while preserving training consistency. |
| 2020-06-19
DDPM (notes in jupyter) |
Denoising Diffusion Probabilistic Models (NeurIPS 2020)

|
Denoising diffusion probabilistic models that iteratively denoises data from random noise for image generation. |
| 2019-06-02
VQ-VAE-2 |
Generating Diverse High-Fidelity Images with VQ-VAE-2 (NeurIPS 2019) | Introduce hierarchical VQ-VAE and make sampling in the compressed latent space (which is faster than sampling in pixel space), inspired by the idea of lossy compression. |
| 2017-11-02
VQ-VAE |
Neural Discrete Representation Learning (NeurIPS 2017) | Propose vector quantised variational autoencoder to generate discrete codes while the prior is also learned. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2024-11-27 Reliable Seed |
Enhancing Compositional Text-to-Image Generation with Reliable Random Seeds (ICLR 2025) | The noises initialized by reliable seeds result in accurate image generation such as numeracy and position, and use these generated data for fine-tuning further improves performance. |
| 2024-03-08 ELLA |
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment (arXiv 2024)

|
ELLA: Replace CLIP with LLM to understand dense prompts; DPG-Bench: evaluate image generation on dense prompts. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-01-23 PARM |
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step (arXiv 2025)

|
Apply Chain-of-Thought into image generation and combine it with reinforcement learning to further improve performance. |
| 2025-01-23 Flow-RWR Flow-DPO |
Improving Video Generation with Human Feedback (arXiv 2025)

|
A human preference video dataset; Adapt diffusion-based reinforcement learning to flow-based video generation models. |
| 2023-12-19 InstructVideo |
InstructVideo: Instructing Video Diffusion Models with Human Feedback (CVPR 2024)

|
Use HPS v2 to provide reward and train video generation models in an editing manner. |
| 2023-11-21 Diffusion-DPO (notes in jupyter) |
Diffusion Model Alignment Using Direct Preference Optimization (CVPR 2024)

|
Adapt Direct Preference Optimization (DPO) from large language models to diffusion models for image generation. |
| 2022-12-19 promptist |
Optimizing Prompts for Text-to-Image Generation (NeurIPS 2023)

|
Use LLM to refine prompts for preference-aligned image generation by taking relevance and aesthetics as reward. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2024-03-18 SD3-Turbo LADD |
Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation (SIGGRAPH Asia 2024) | Perform distillation of diffusion models in latent space using teacher-synthetic data and optimizing only an adversarial loss with the teacher as the discriminator. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-02-24 IGTR |
Autoregressive Image Generation Guided by Chains of Thought (arXiv 2025) | Insert reasoning prompts to improve auto-regressive image generation performance by Chain-of-Thought. |
| 2025-01-23 PARM |
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step (arXiv 2025)
|
Apply Chain-of-Thought into image generation and combine it with reinforcement learning to further improve performance. |
|
2025-01-16 Scaling Analysis |
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps (CVPR 2025) | Analysis on inference-time scaling of diffusion models for image generation from the axes of verifiers and algorithms. |
|
2024-12-14 Z-Sampling |
Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection (ICLR 2025)

|
Use guidance gap between denosing and inversion and iteratively perform them to improve image generation quality. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-03-07 UnifiedReward |
Unified Reward Model for Multimodal Understanding and Generation(arXiv 2025)

|
A unified reward model for both multimodal understanding & generation evaluation by pairwise ranking & pointwise scoring. |
| 2024-12-24 FGA-BLIP2 |
EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation (arXiv 2024)

|
Use 40K image-text pairs with fine-grained human annotations for image generation evaluation. |
| 2024-07-19 T2V-CompBench |
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation (arXiv 2024)

|
Use 1400 prompts to evaluate video generation on compositional generation, including consistent attribute binding, dynamic attribute binding, sptial relationships, motion binding, action binding, object interations, generative numeracy. |
| 2024-05-23 MPS |
Learning Multi-dimensional Human Preference for Text-to-Image Generation (CVPR 2024)

|
Apply condition upon CLIP to learn multi-dimensional preference score: aesthetics & alignment & detail & overall, trained on a dataset with 92K preference choices of 61K images. |
| 2024-04-01 VQAScore |
Evaluating Text-to-Visual Generation with Image-to-Text Generation (ECCV 2024)

|
VQAScore: alignment probability of "yes" answer from a VQA model with CLIP-FlanT5 structure; GenAI-Bench: evaluation benchmark with 1600 prompts for image generation. |
| 2024-03-08 DPG-Bench |
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment (arXiv 2024)
|
ELLA: Replace CLIP with LLM to understand dense prompts; DPG-Bench: evaluate image generation on dense prompts. |
| 2023-11-29 VBench |
VBench: Comprehensive Benchmark Suite for Video Generative Models (CVPR 2024)

|
Evaluate video generation from 16 dimensions within the perspectives of video quality and video-prompt consistency. |
| 2023-10-17 GenEval |
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment (NeurIPS 2023)

|
An object-focused framework for image generation evaluation by providing scores of single object, two objects, counting, colors, position, attribute binding, and overall. |
|
2023-07-12 T2I-CompBench (notes in jupyter) |
T2I-CompBench: A Comprehensive Benchmark for Open-world Compositional Text-to-image Generation (NeurIPS 2023)

|
Use 6000 prompts to train and evaluate image generation on compositional generation, including attribute binding, object relationship, and complex compositions. |
| 2023-06-15 HPS v2 (notes in jupyter) |
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis (arXiv 2023)

|
HPD v2: 798K binary human preference choices on 433K pairs of generated images; HPS v2: use HPD v2 to fine-tune CLIP for image generation evaluation. |
| 2023-05-02 PickScore (notes in jupyter) |
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation (NeurIPS 2023)

|
Pick-a-Pic: use a web app to collect user preferences; PickScore: train a CLIP-based model for image generation evaluation. |
| 2023-04-12 ImageReward (notes in jupyter) |
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation (NeurIPS 2023)

|
Train BLIP on 137K human preference image pairs for image generation and use it to tune diffusion models by Reward Feedback Learning (ReFL). |
| 2023-03-25 HPS |
Human Preference Score: Better Aligning Text-to-Image Models with Human Preference (ICCV 2023)

|
Fine-tune CLIP using annotated 98K SD generated images from 25K prompts for image generation evaluation. |
| 2021-04-18 CLIPScore (notes in jupyter) |
CLIPScore: A Reference-free Evaluation Metric for Image Captioning (EMNLP 2021)

|
A reference-free metric mainly focusing on semantic alignment for image generation evaluation. |
| 2019-05-04 FVD |
FVD: A new Metric for Video Generation (ICLR workshop 2019) | Extend FID for video generation evaluation by replacing 2D InceptionNet with pre-trained Inflated 3D convnet. |
| 2017-06-26 FID (notes in jupyter) |
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium (NeurIPS 2017) | Calculate Fréchet distance between Gaussian distributions of InceptionNet feature maps of real-world data and synthetic data for image generation evaluation. |
| 2016-06-10 Inception Score (notes in jupyter) |
Improved Techniques for Training GANs (NeurIPS 2016)

|
Calculate KL divergence between p(y|x) and p(y) that aims to minimize the entropy across samples and maximize the entropy across classes for image generation evaluation. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-04-24 Step1X-Edit |
Step1X-Edit: A Practical Framework for General Image Editing (arXiv 2025)

|
Use a MLLM to generate condition embedding of the reference image and user's editing instruction, trained on 20M instruction-image data for image generation editing. |
Authors: Step1X-Image Team
Organizations: StepFun
Summary: Use a MLLM to generate condition embedding of the reference image and user's editing instruction, trained on 20M instruction-image data for image generation editing.
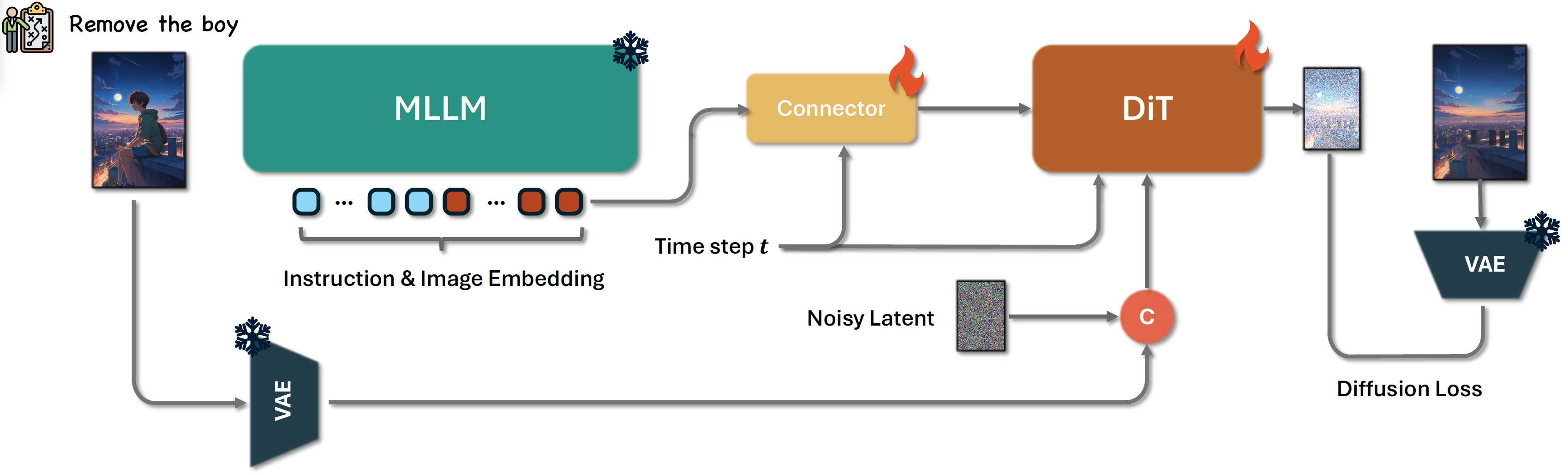
|
Project: SimpleAR
Authors: Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, Yu-Gang Jiang
Organizations: Fudan University, ByteDance Seed
Summary: A vanilla, open-sourced AR model (0.5B) for 1K text-to-image generation, trained by pre-training, SFT, RL (GRPO), acceleration (KV cache, vLLM serving, speculative jacobi decoding).
Project: Seedream 3.0
Authors: ByteDance Seed Vision Team
Organizations: ByteDance
Summary: ByteDance Sead Vision Team's text-to-image generation model (MMDiT structure), improve Seedream 2.0 by defect-aware training, representation alignment, larger reward model, etc.
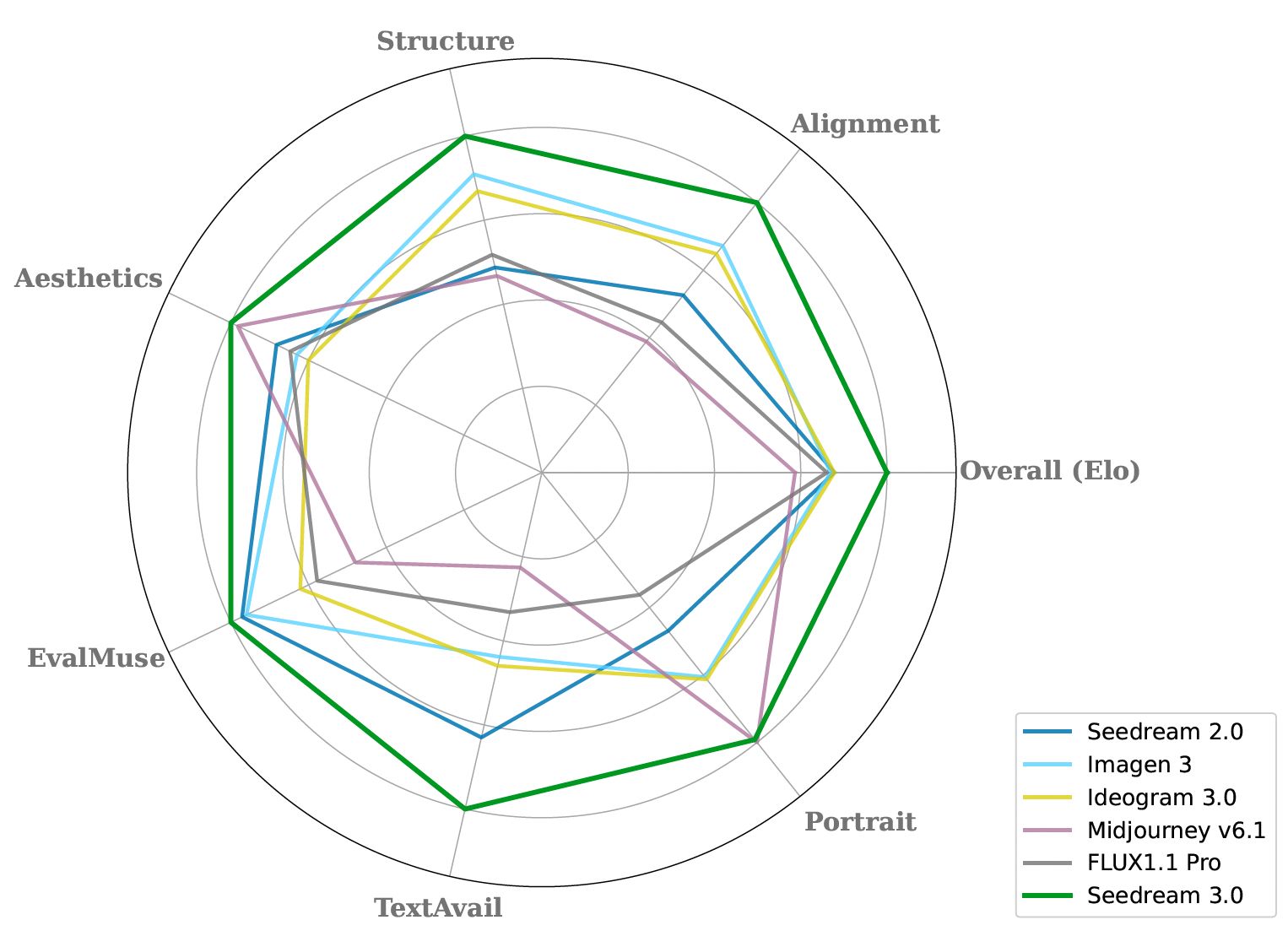
|
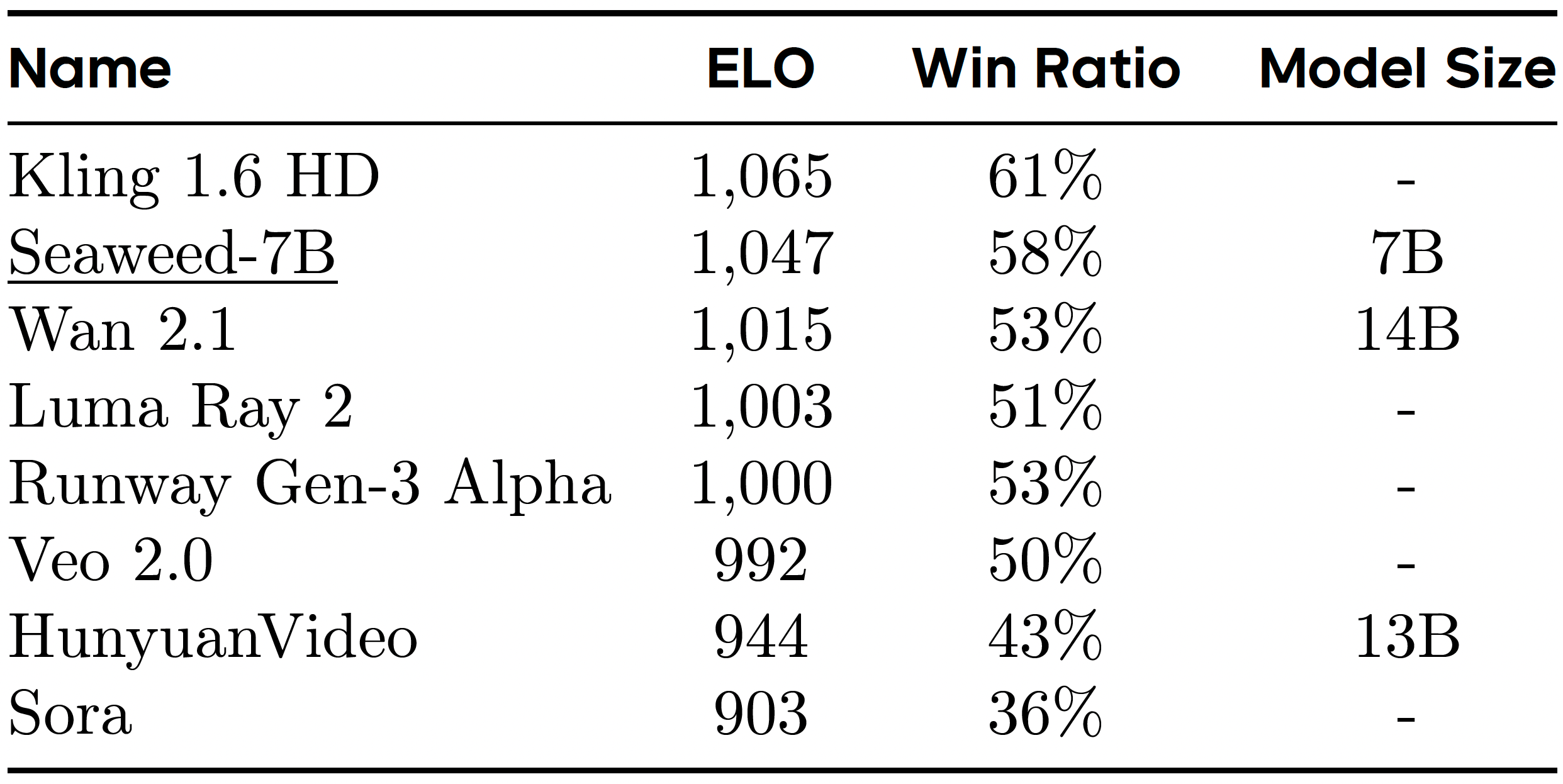
Project: Seaweed-7B
Authors: ByteDance Seaweed Team
Organizations: ByteDance
Summary: ByteDance Seaweed Team's text-to-video & image-to-video generation model (7B) with DiT structure, trained (multi-task learning) on O(100M) video clips using 665K H100 GPU hours.

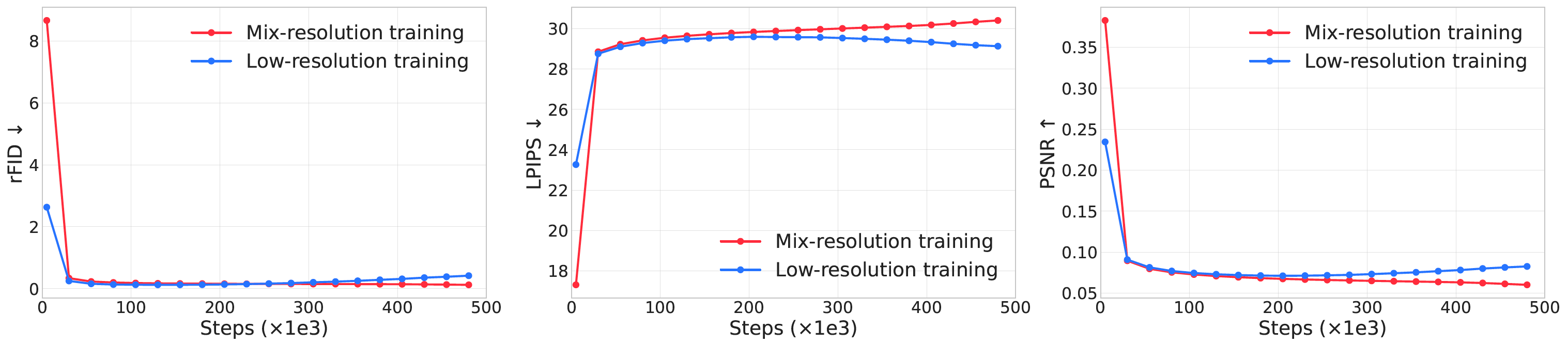
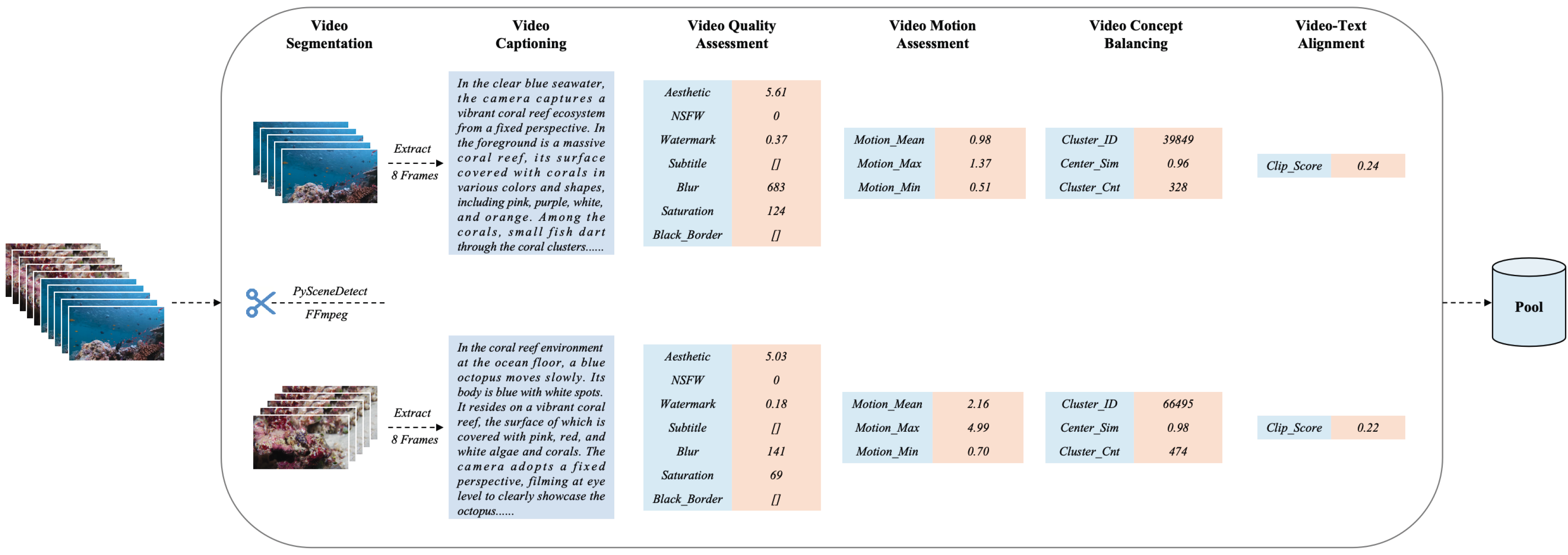
Temporal splitting: internal splitter. Spatial cropping: use FFmpeg to remove black border, and develop models for text, logo, watermark, and special effects detection; Quality filtering: >256 pixels, within [1/3, 3/1] aspect ratio, elimitenate static clips and undeseirable movements, camera shake & playback speed detection, safety, artifact detection. Multi-aspect data balancing & video deduplication: clustering. Simulation data: use graphics engines to synthesize videos. Video captioning: a short & a long caption. System prompt: video types, camera position, camera angles, camera movement, visual styles. |
|
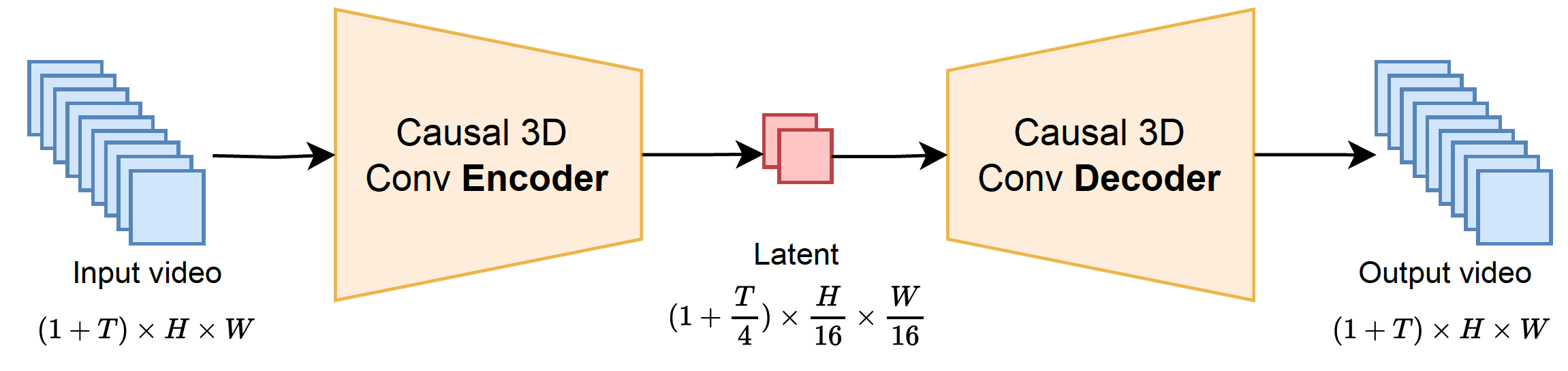
|
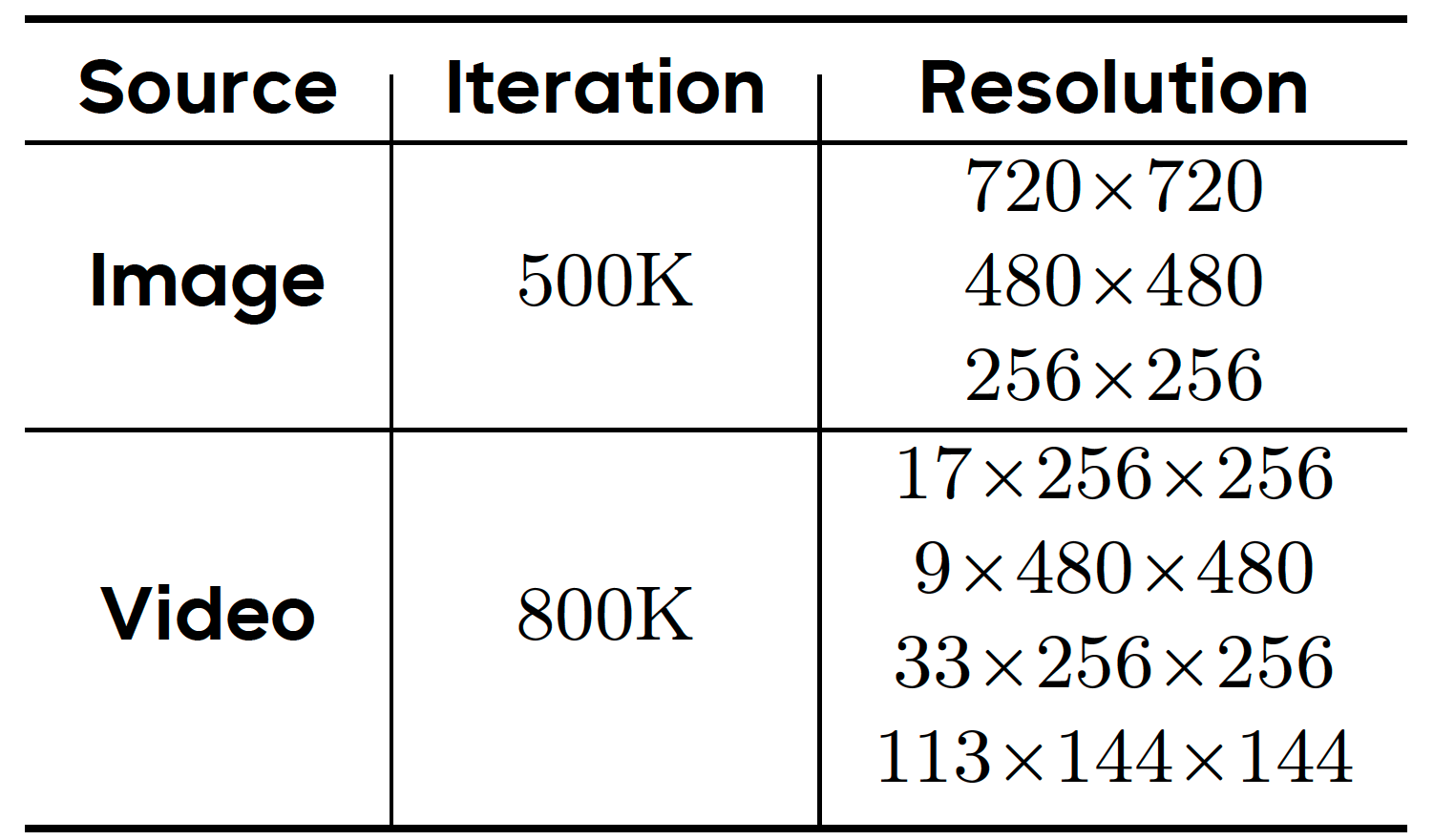
|
|
|
|
|

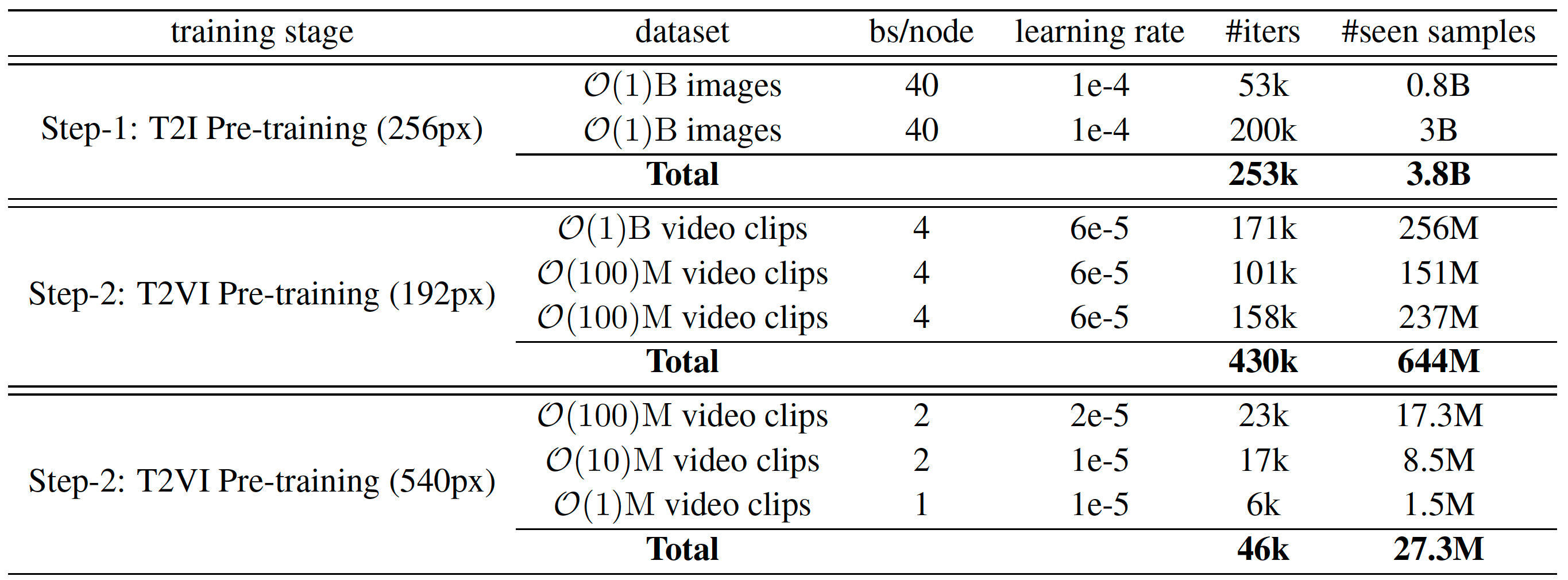
Use multi-task training: text-to-video, image-to-video, video-to-video. Input features and conditioning features are channel-concatenated, with a binary mask indicating the condition. Ratio of image-to-video is 20% during pre-training, and increasing to 50%-75% detached for fine-tuning. SFT: use 700K good videos and 50K top videos, the following ability drops a little. RLHF: lr=1e-7, beta=100, select from 4 samples from different seeds. Distillation: trajectory segmented consistency distillation + CFG distillation + adversarial training, distill to 8 steps. |
|
|
|
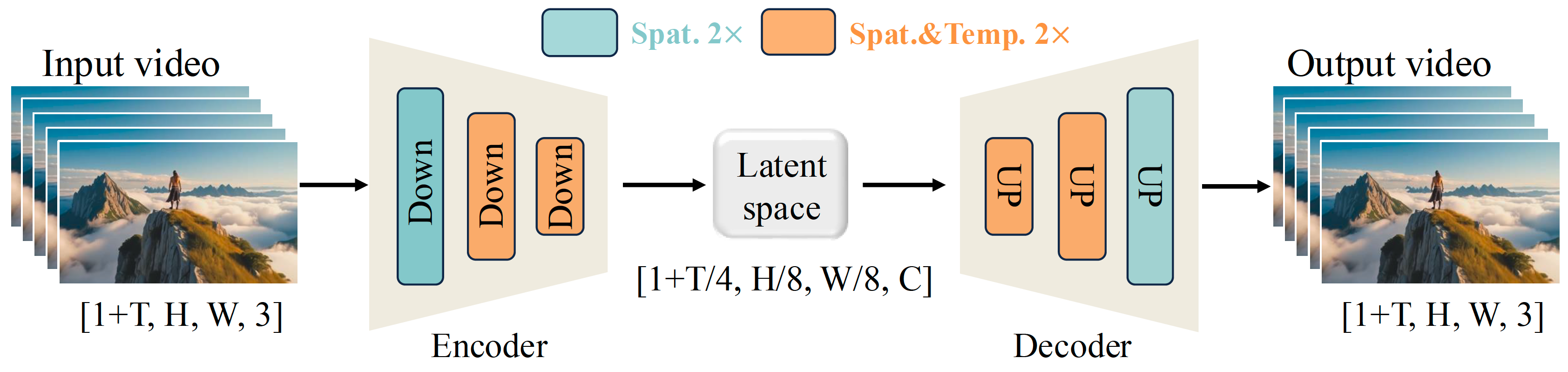
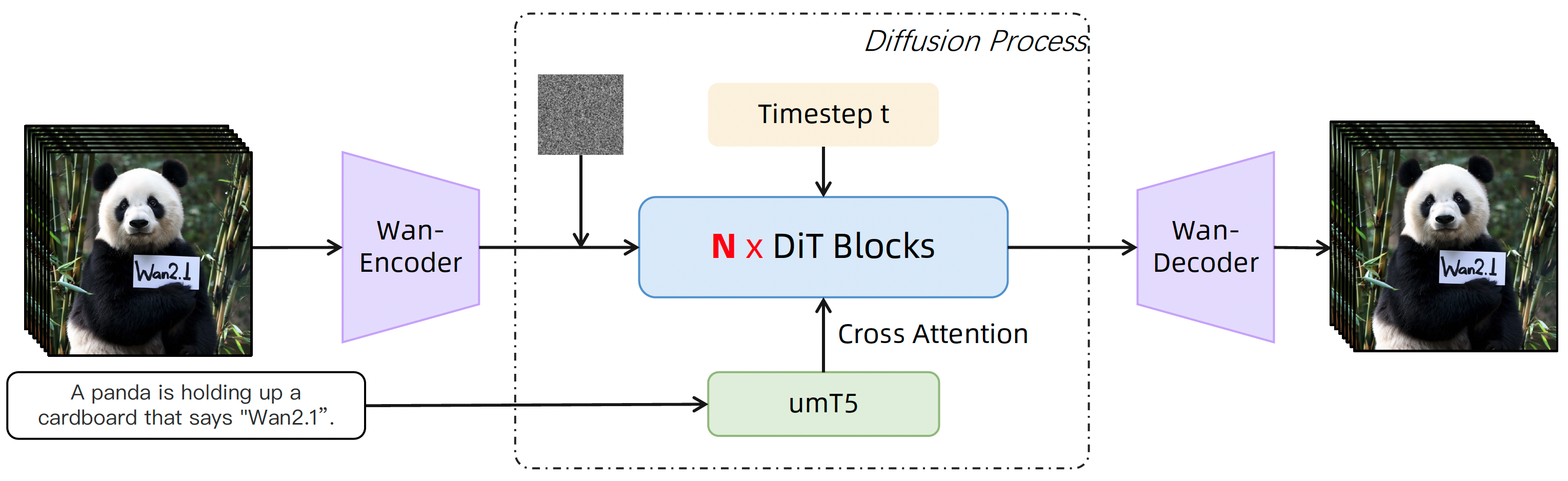
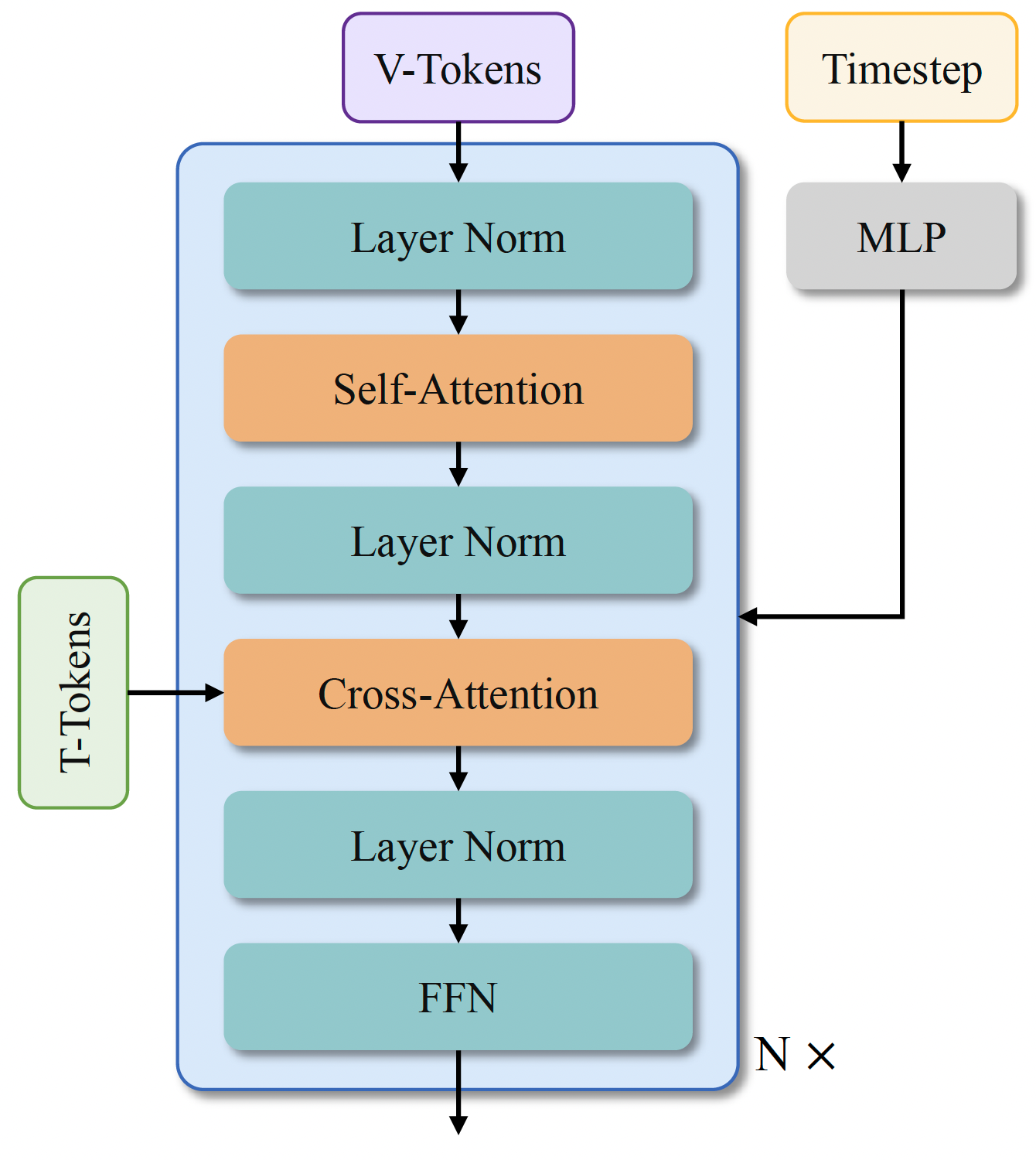
Project: Wan
Authors: Wan
Organizations: Alibaba Group
Summary: Alibaba Tongyi Wanxiang's open-sourced model (14B) for text-to-video & image-to-video generation, using 8x8x4 VAE, DiT structure, etc.
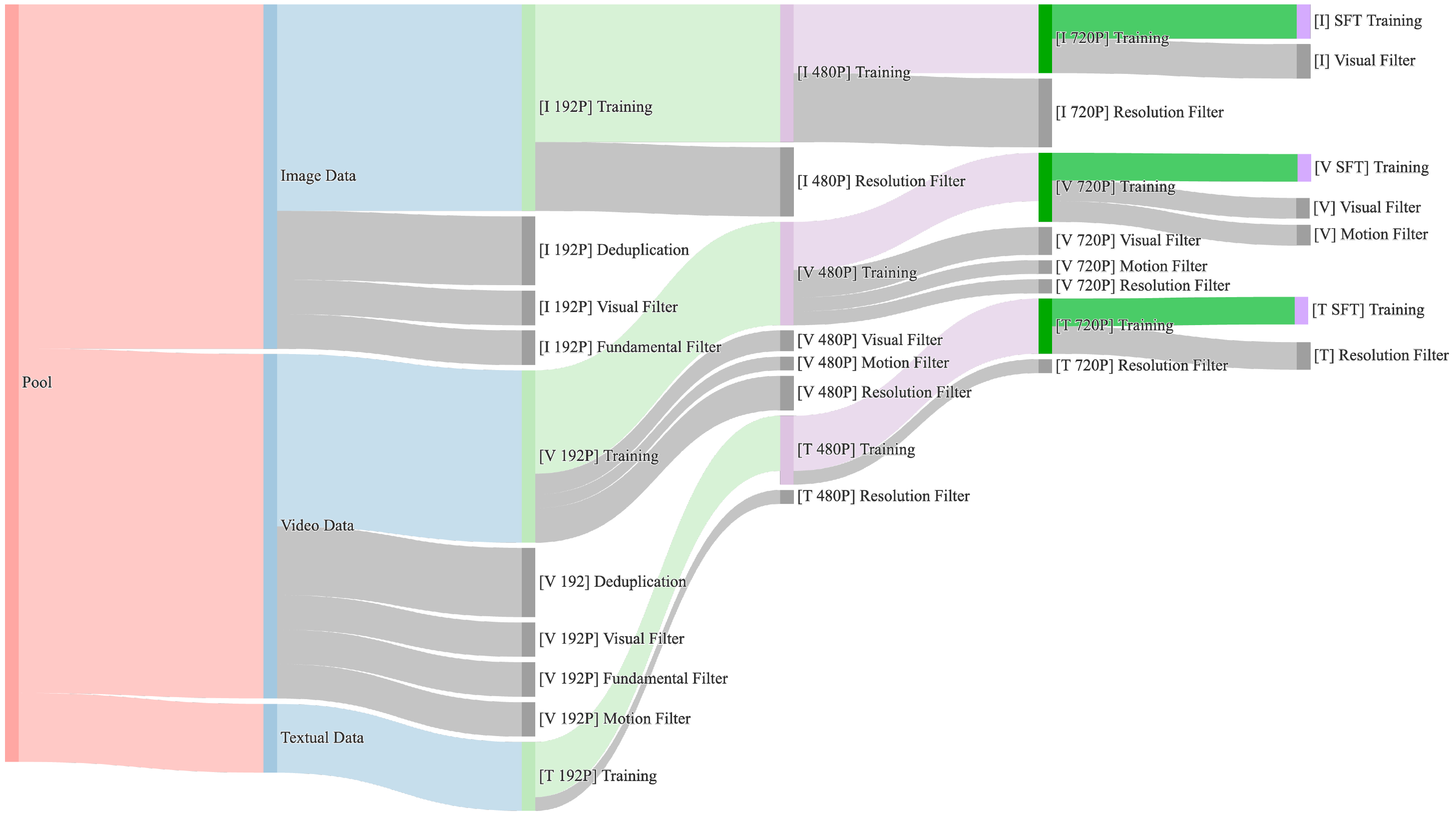
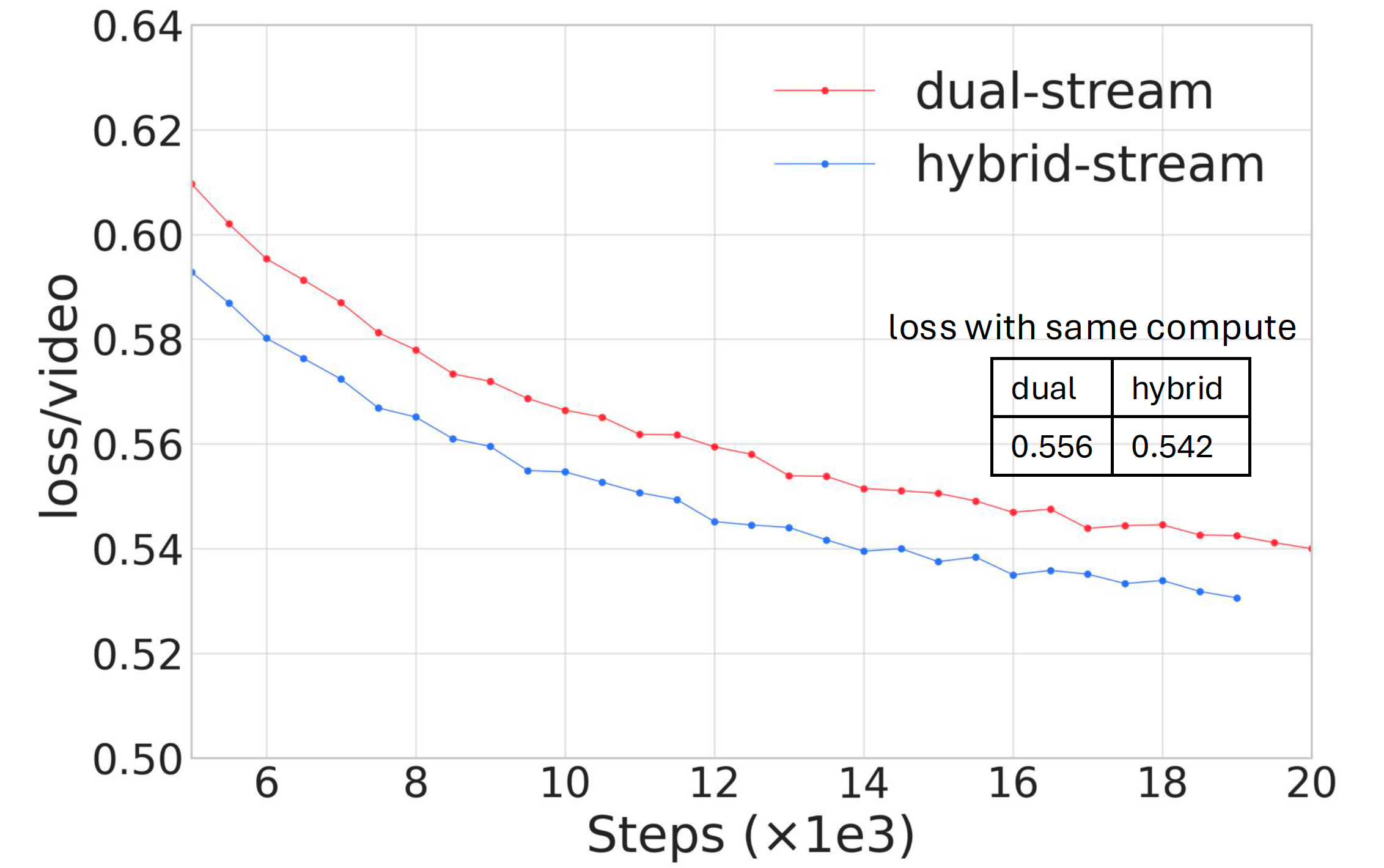
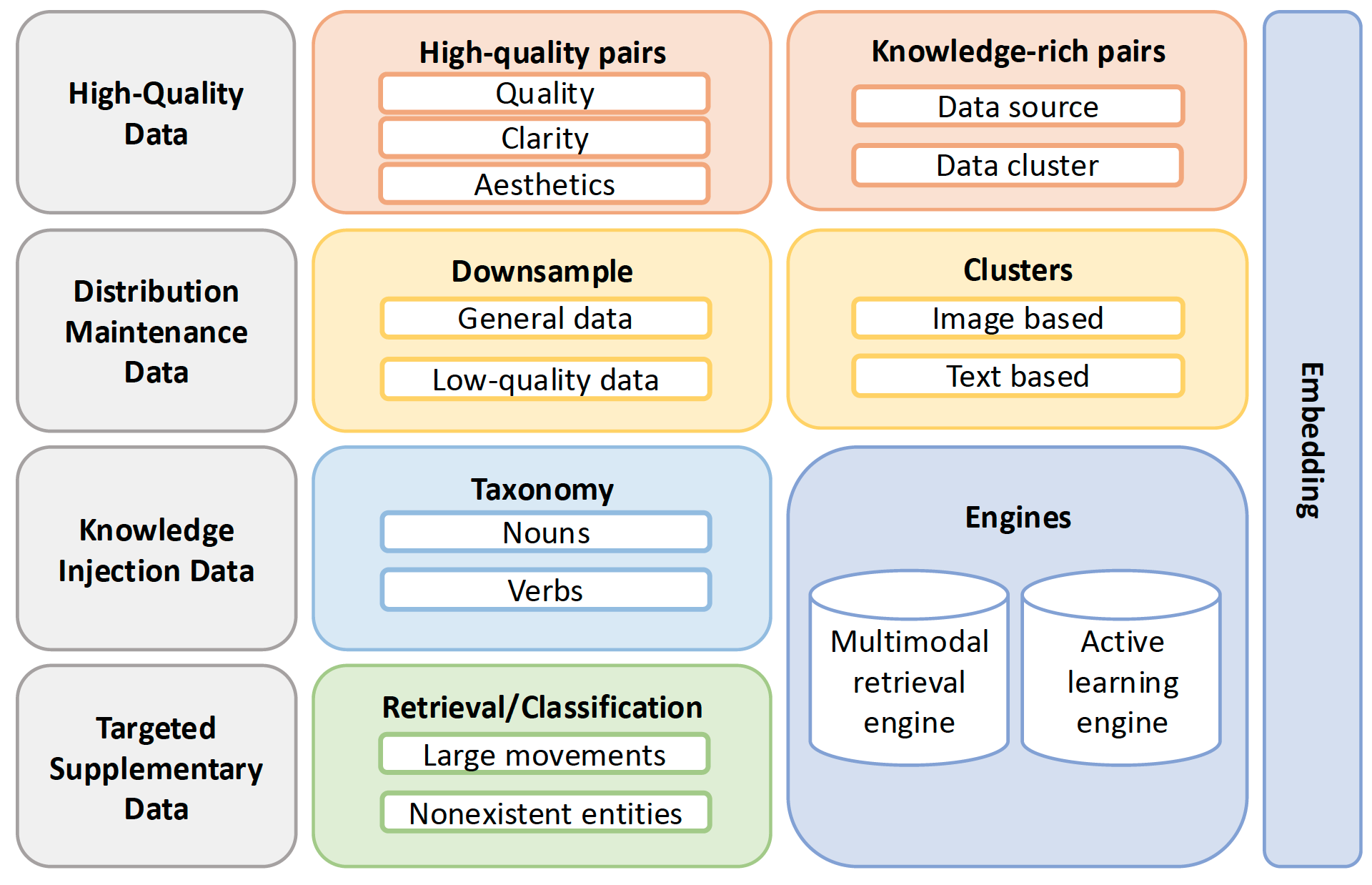
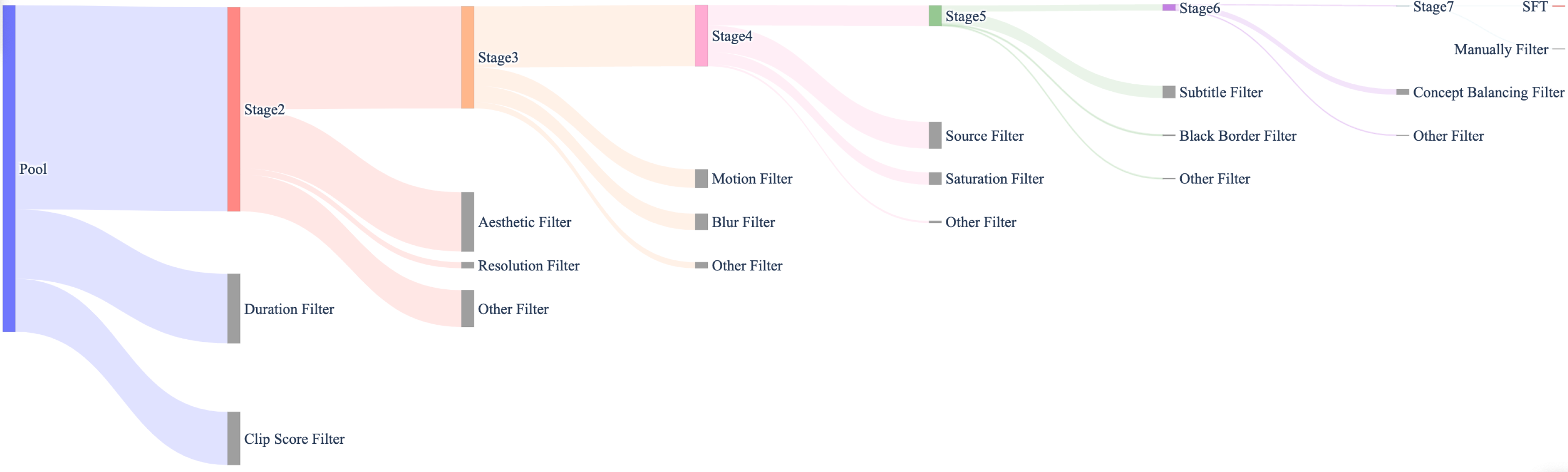
Fundamental dimensions: text detection, aesthetic evaluation, NSFW score, watermark & logo detection, black border detection, overexposure detection, synthetic image detection, blur detection, duration & resolution. Visual quality: clustering, scoring. Motion quality: optimal motion, medium-quality motion, static videos, camera-driven motion, low-quality motion, shaky camera footage. Visual text data: hundreds of millions of text-containing images by rendering Chinese characters on a pure white background and large amounts from real-world data. Captions: celebrities, landmarks, movie characters, object counting, OCR, camera angle and motion, fine-grained categories, relational understanding, re-caption, editing instruction caption, group image description, human-annotated image and video captions. |
|
|
|
|
|
|
|
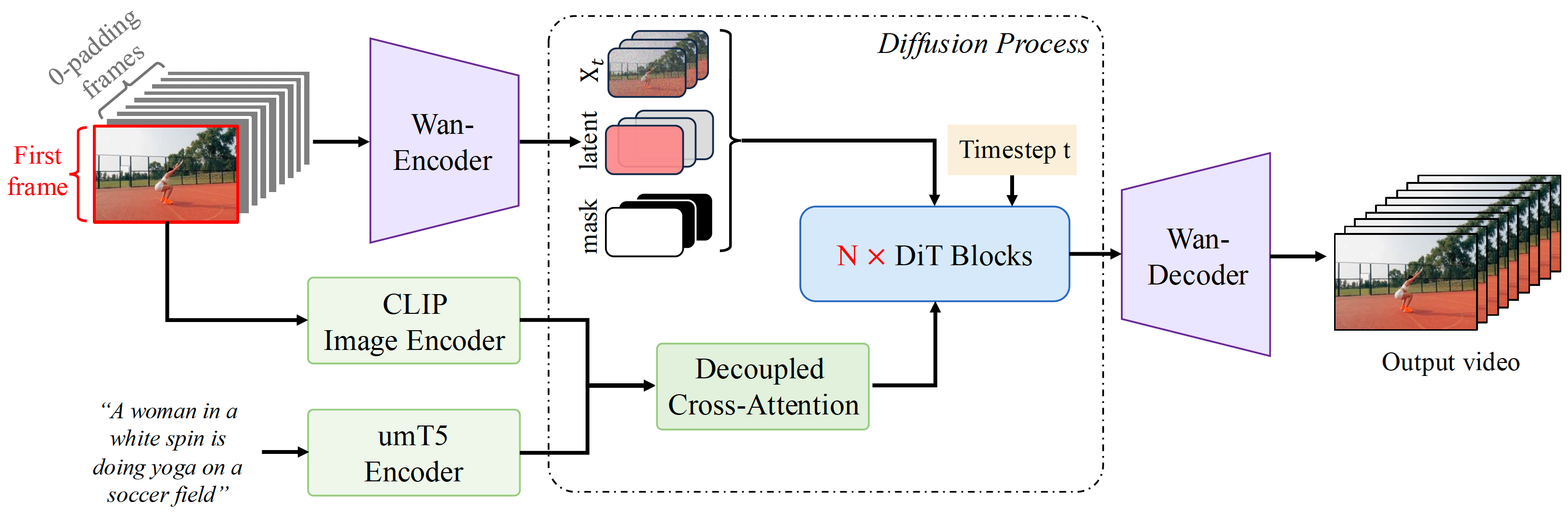
Project: Step-Video-TI2V
Authors: Step-Video Team
Organizations: StepFun
Summary: StepFun's open-sourced model (30B) for image-to-video generation, trained upon Step-Video-T2V, by using channel concat of image condition and timestep-combined motion condition.
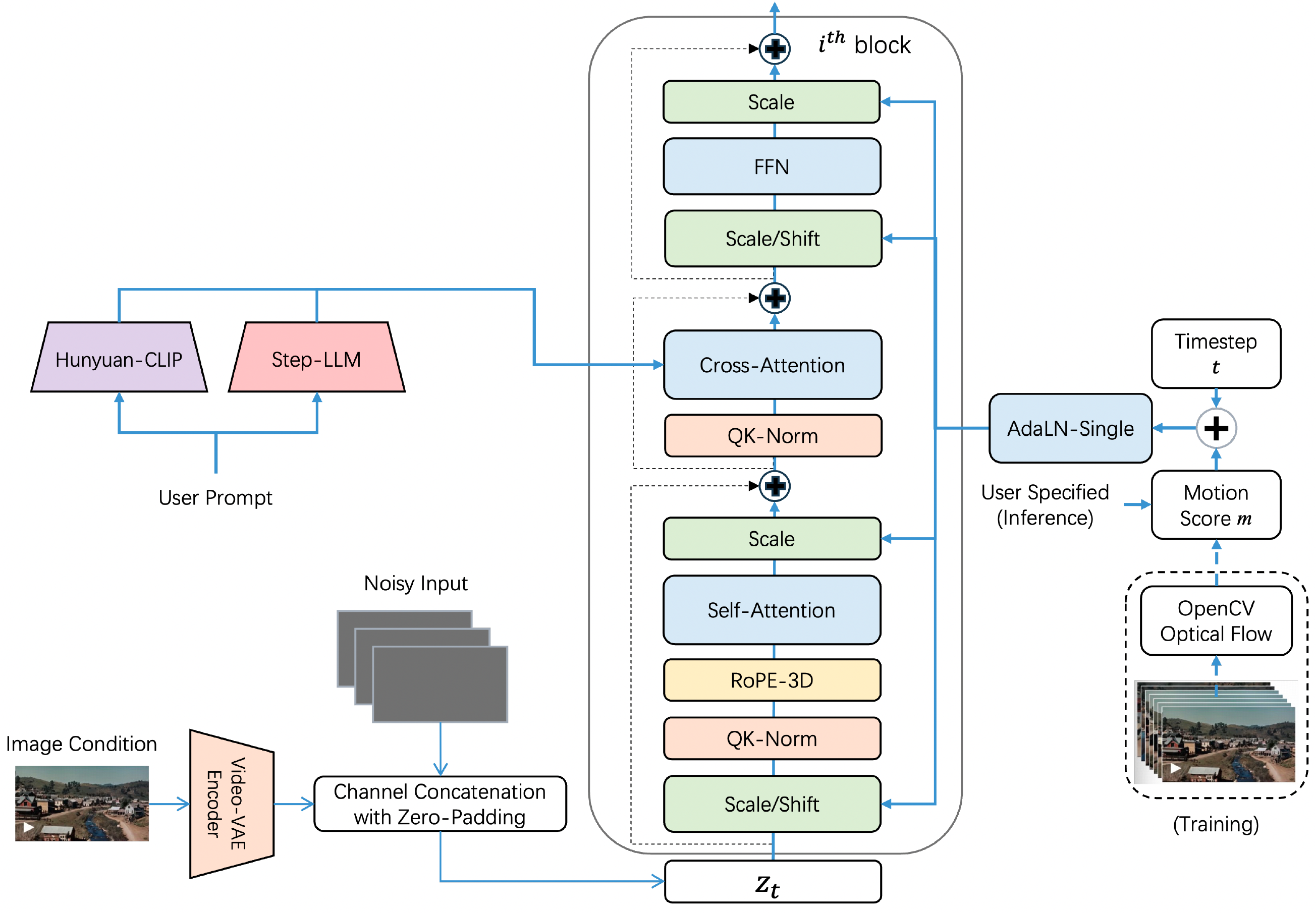
Motion conditioning: motion is extracted using optical flow and is combined with timestep. |
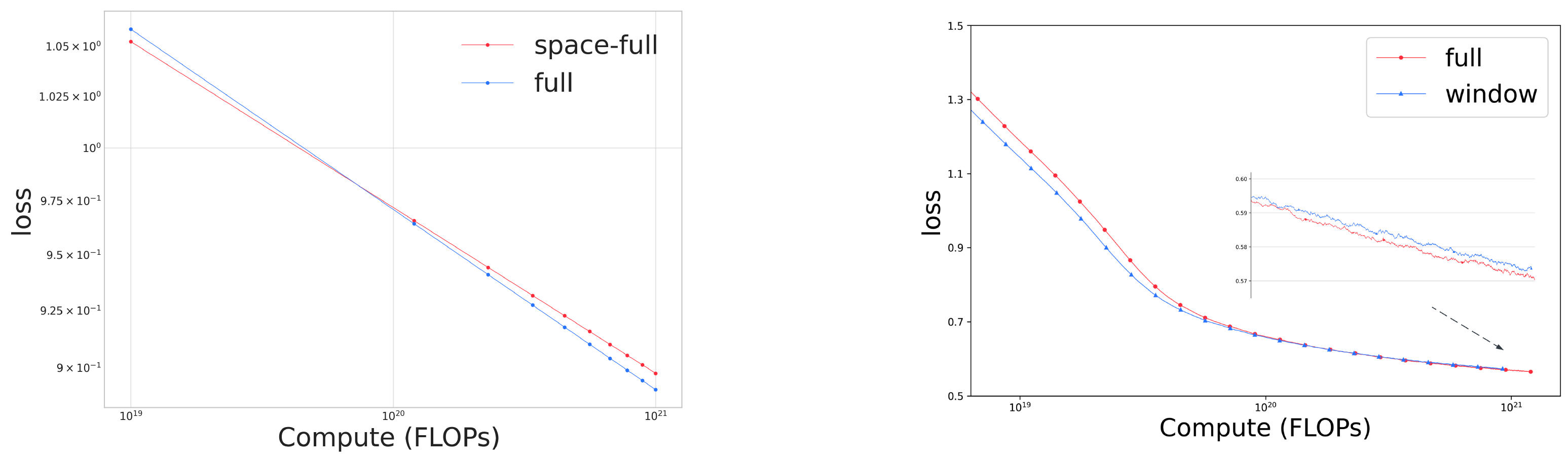
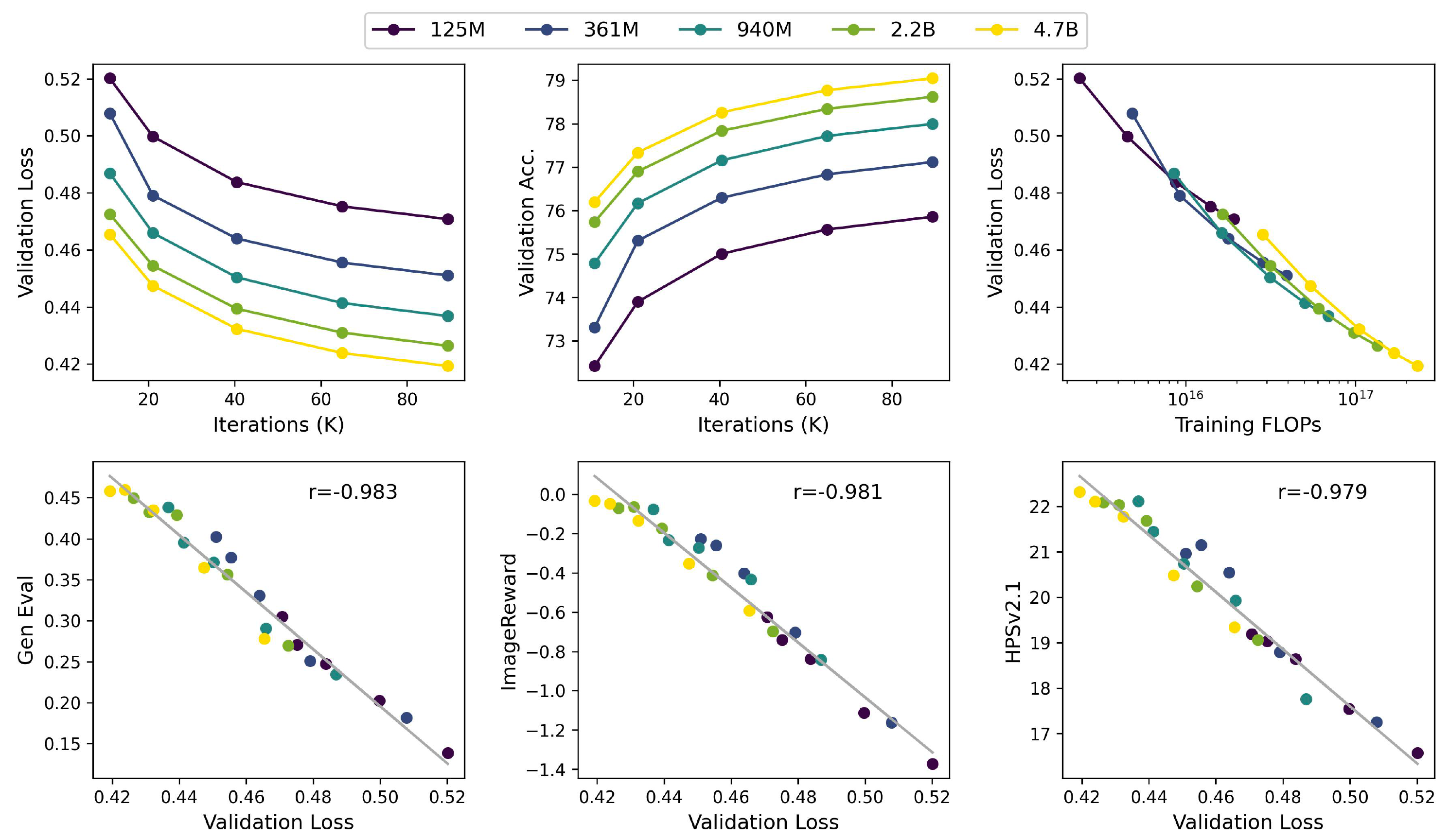
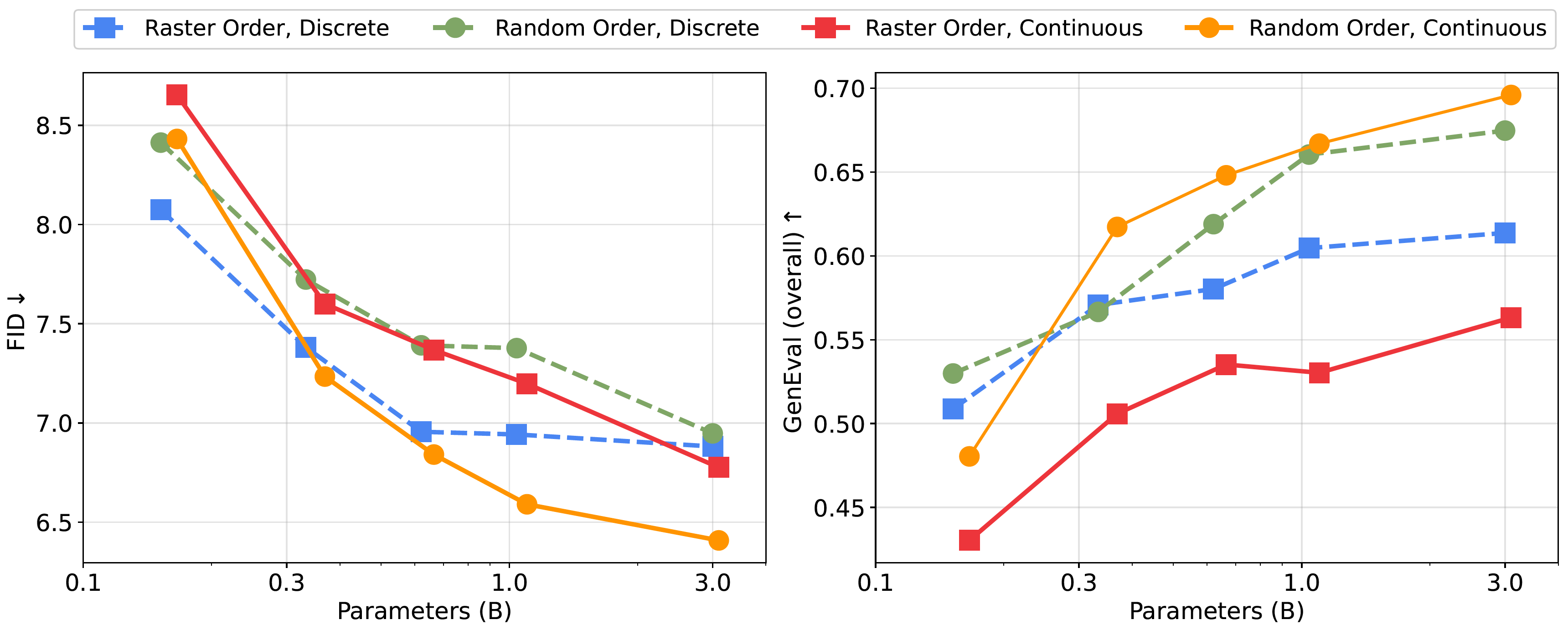
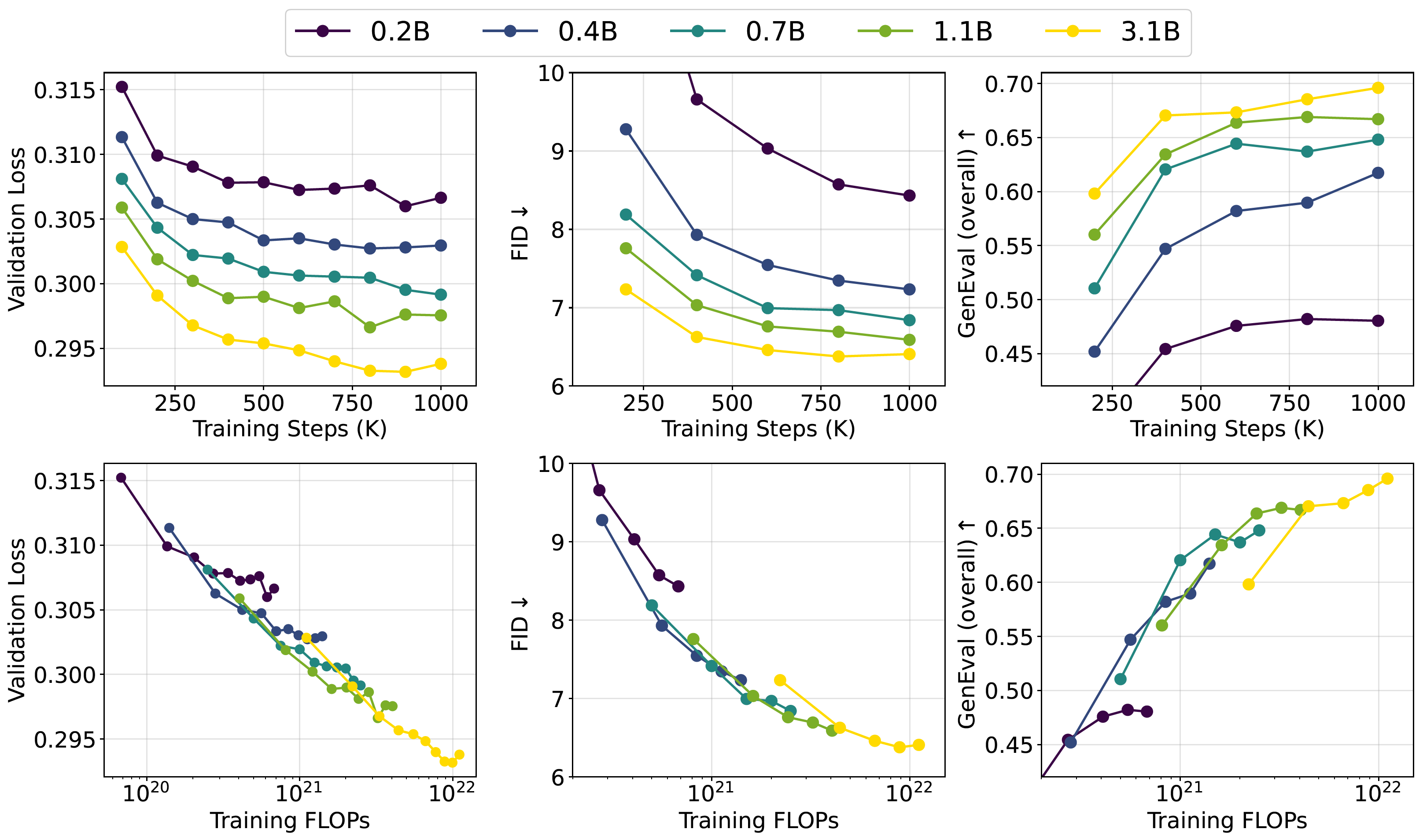
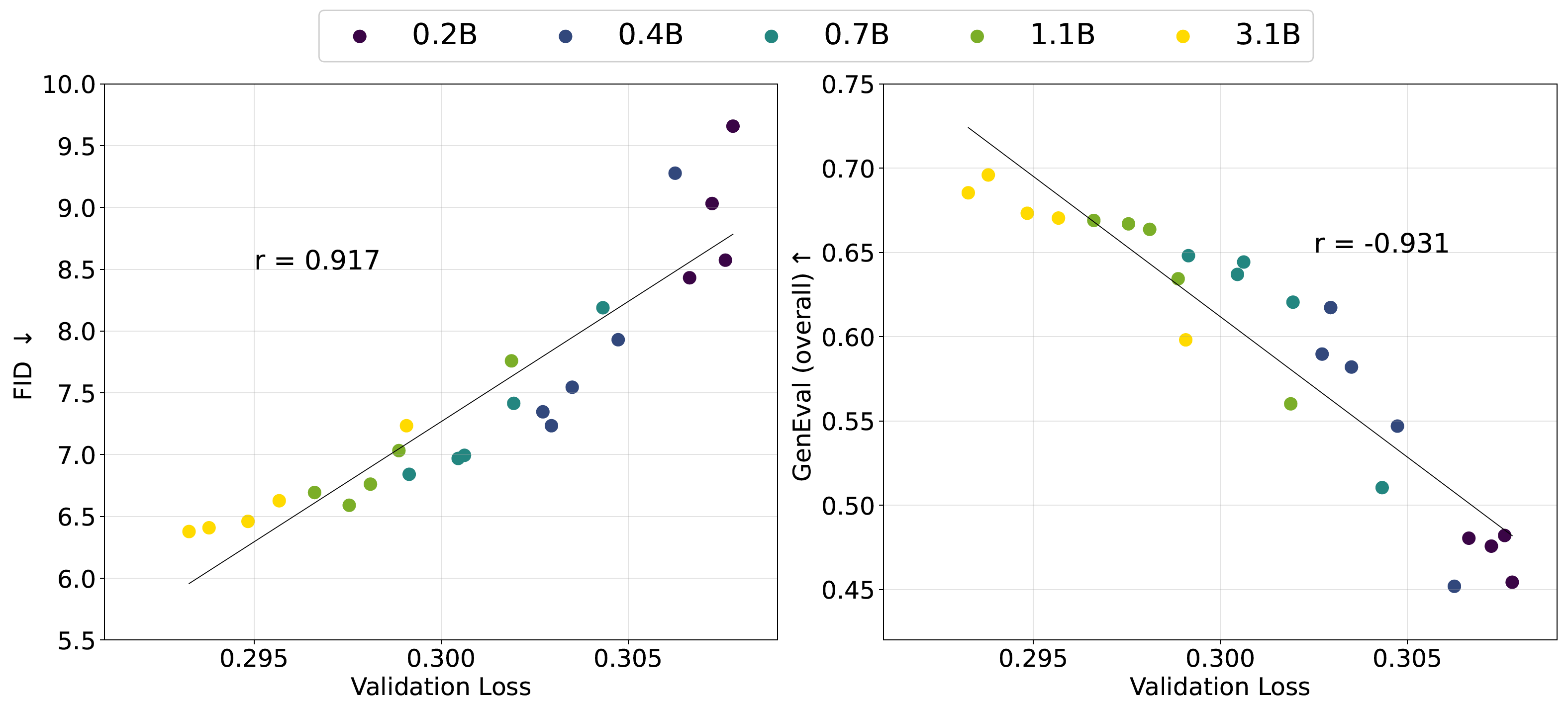
Project: Inference Beat Pretraining
Authors: Jiaming Song, Linqi Zhou
Organizations: Luma AI
Summary: Analyze pre-training algorithm design from a inference-first perspective, and scaling inference from a unified perspective of scaling sequence length & refinement steps.
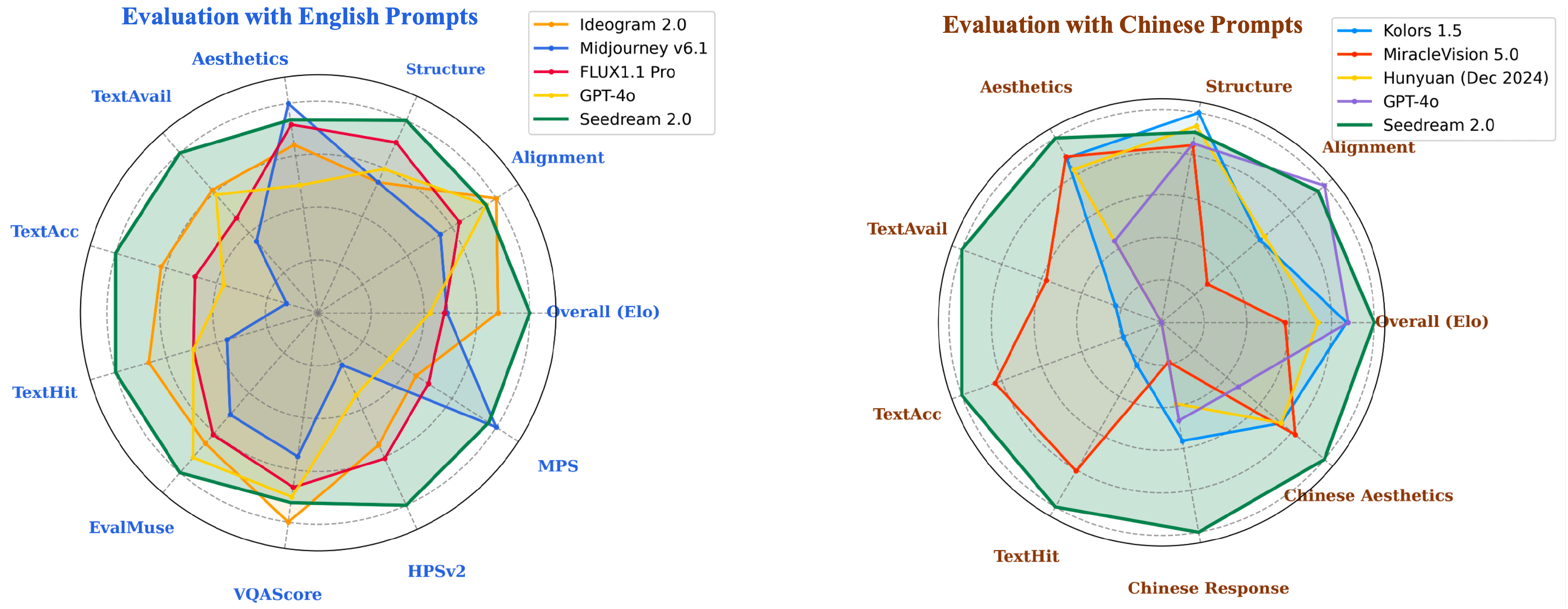
Project: Seedream2.0
Authors: ByteDance's Seed Vision Team
Organizations: ByteDance
Summary: ByteDance Sead Vision Team 's foundation model for image genertion with native Chinese-English bilingual capability, where some techniques such as scaled RoPE, SFT, RLHF are employed.
|
|
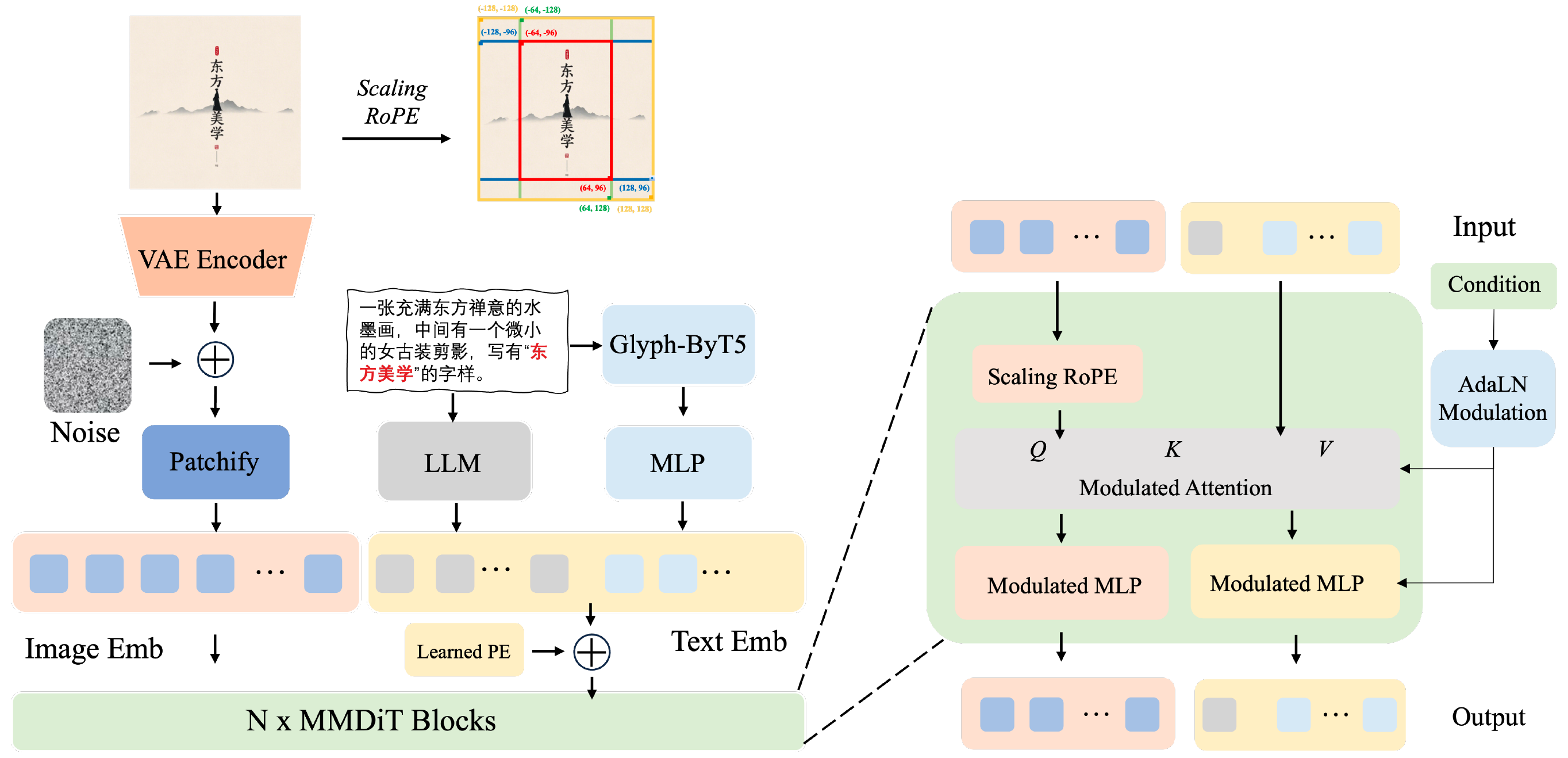
|
|

|
|
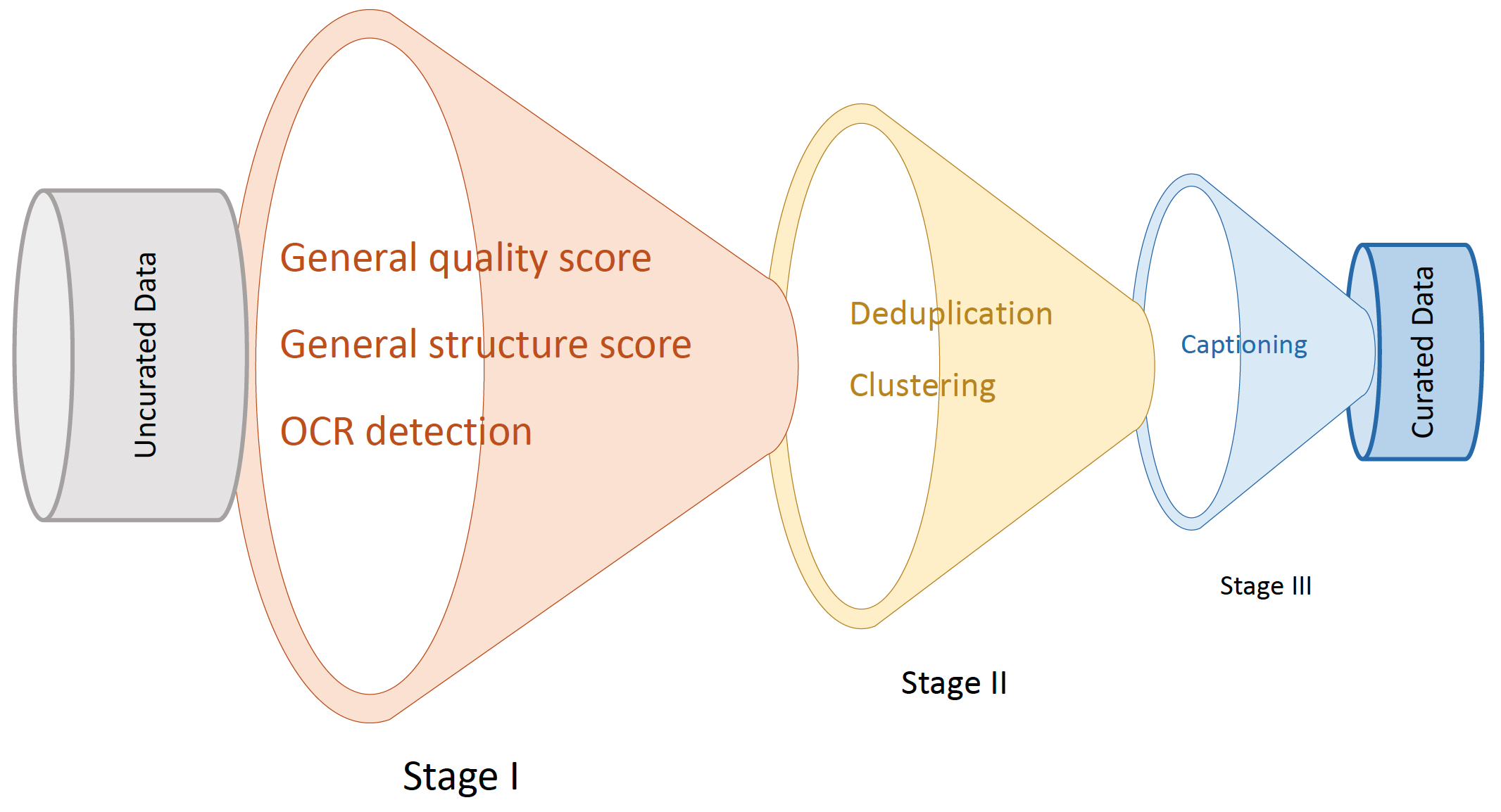
|
|
Project: UnifiedReward
Authors: Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, Jiaqi Wang
Organizations: Fudan University, Shanghai Innovation Institute, Shanghai AI Lab, Shanghai Academy of Artificial Intelligence for Science
Summary: A unified reward model for both multimodal understanding & generation evaluation by pairwise ranking & pointwise scoring.
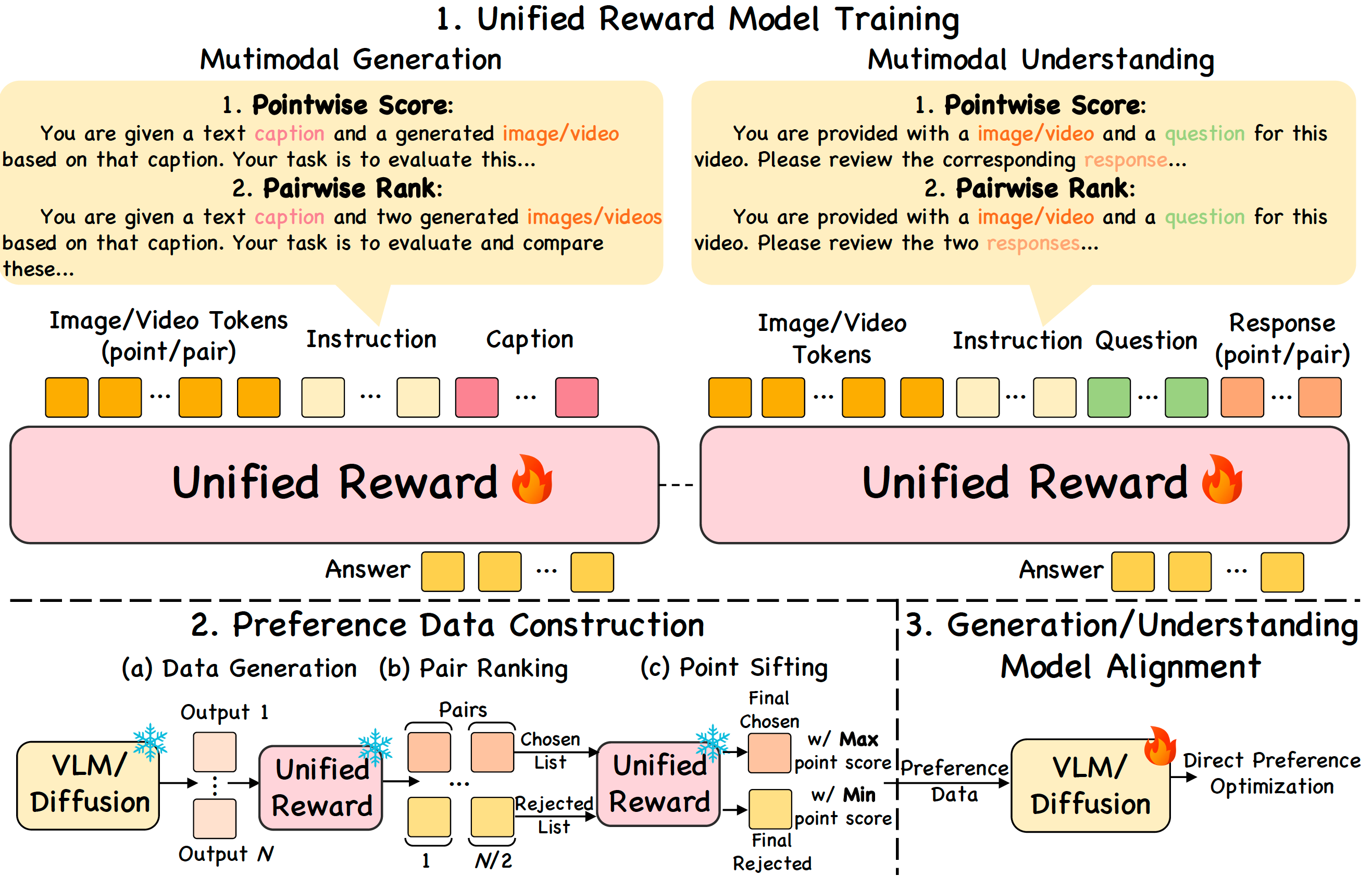
|
Project: IGTR
Authors: Miaomiao Cai, Guanjie Wang, Wei Li, Zhijun Tu, Hanting Chen, Shaohui Lin, Jie Hu
Organizations: University of Science and Technology of China, Huawei Noah's Ark Lab, East China Normal University
Summary: Insert reasoning prompts to improve auto-regressive image generation performance by Chain-of-Thought.
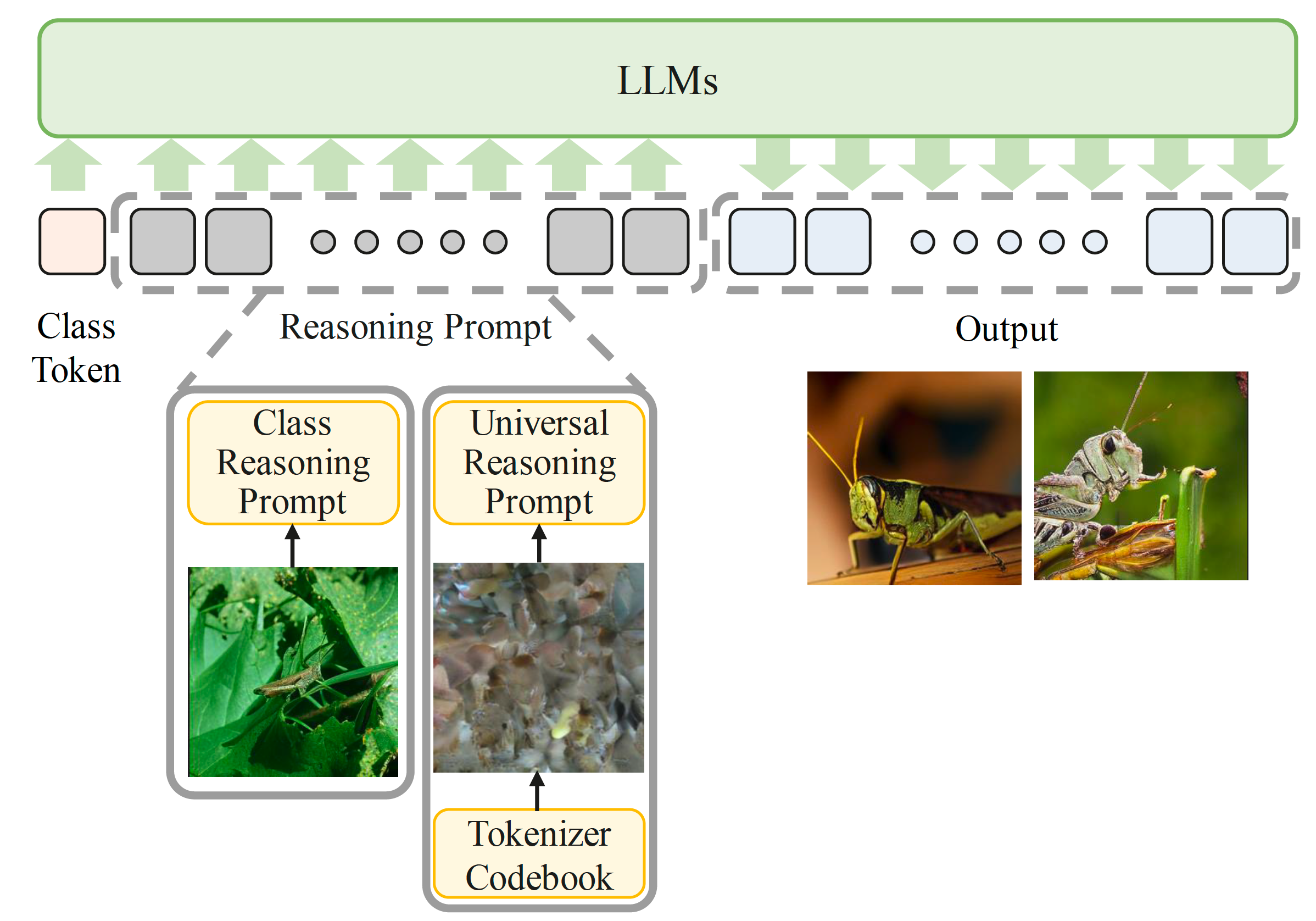
|
Project: noise-unconditional-model
Authors: Qiao Sun, Zhicheng Jiang, Hanhong Zhao, Kaiming He
Organizations: MiT
Summary: Theoretical and empirical analysis on noise-unconditional denoising diffusion models without a timestep input for image generation.
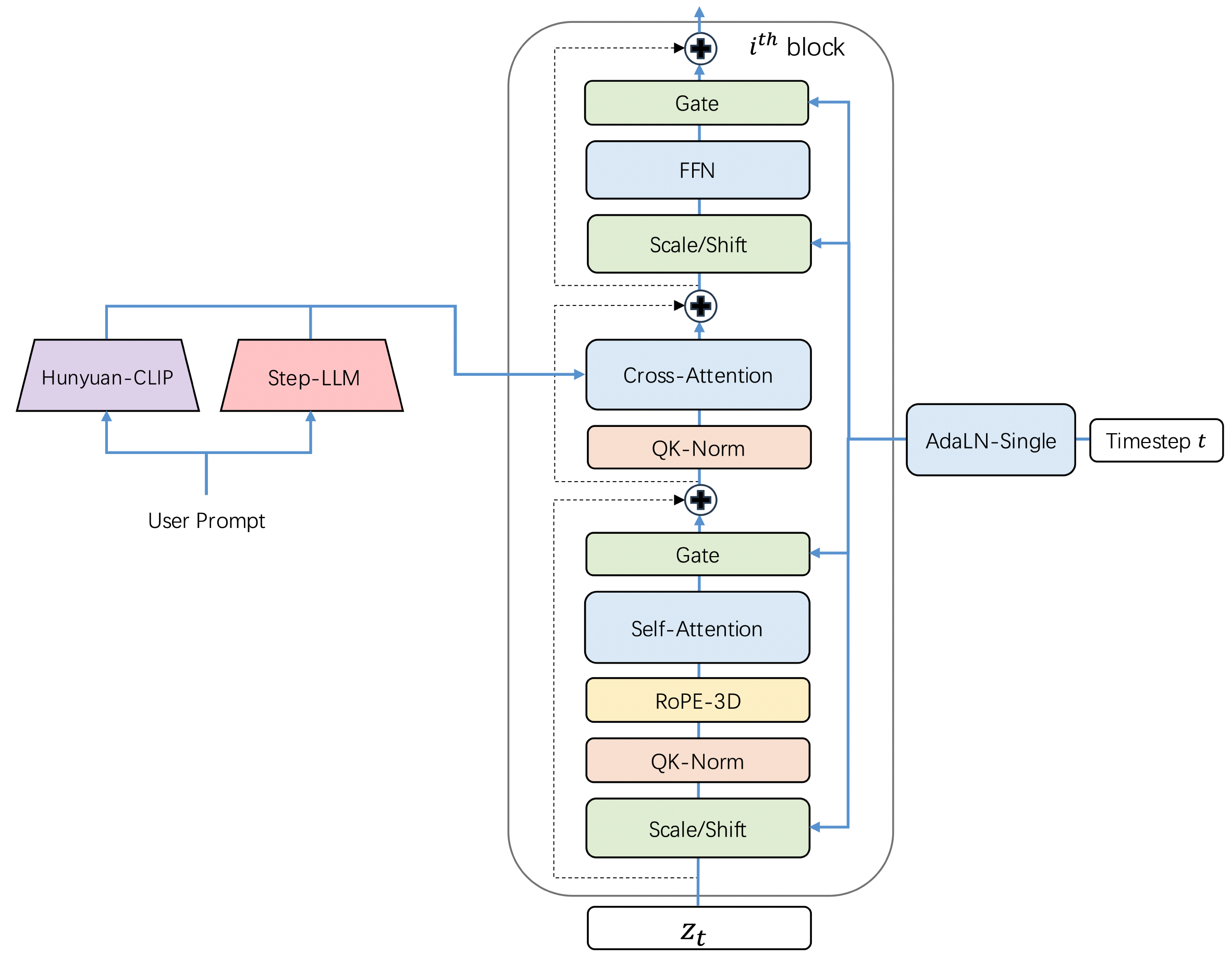
Project: Step-Video-T2V
Authors: Step-Video Team
Organizations: StepFun
Summary: StepFun's open-sourced model (30B) for text-to-video generation, using DiT structure & RoPE-3D & QK-Norm & 16x16x8 VAE & two bilingual text encoders & DPO.
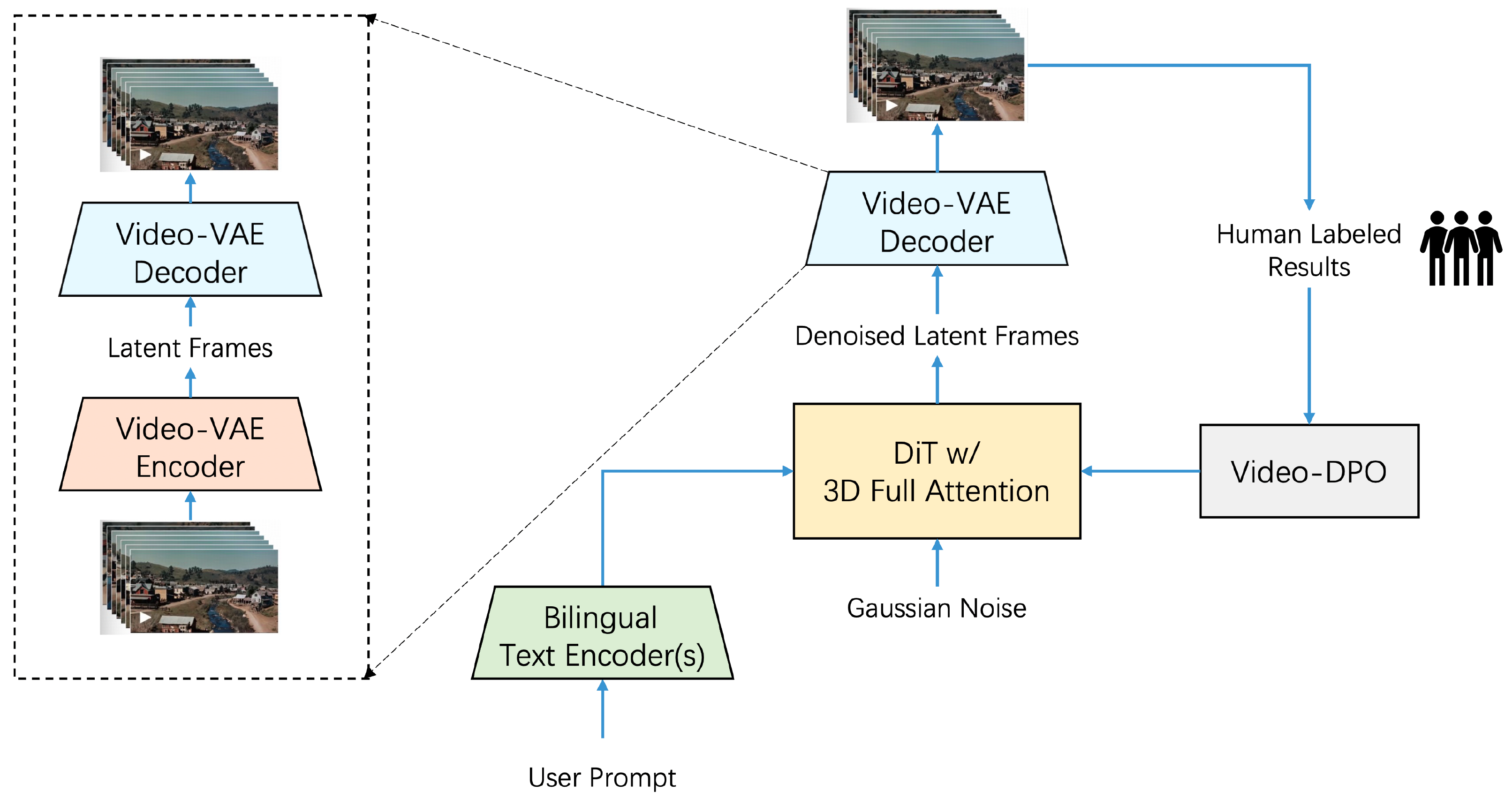
|
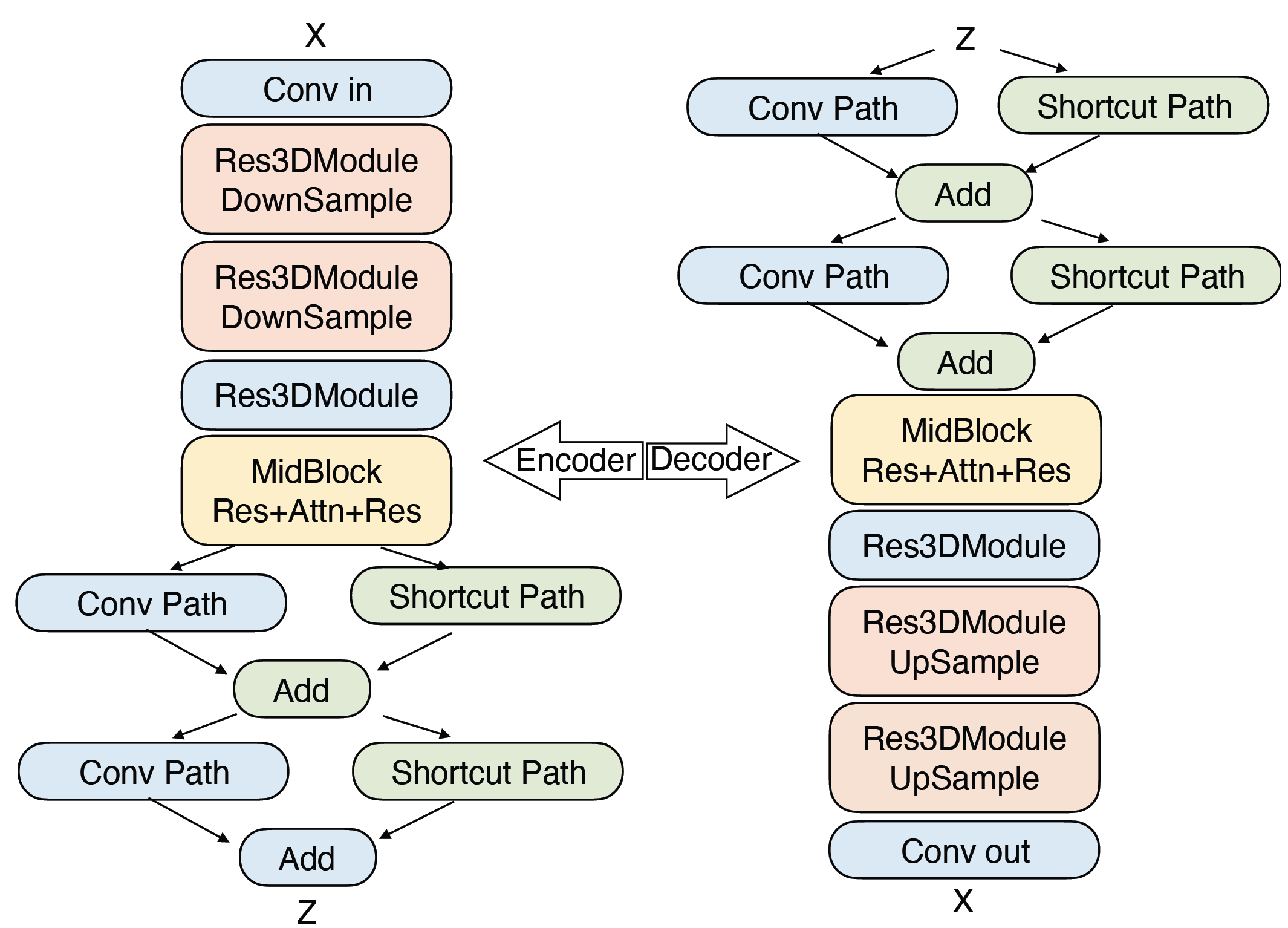
|
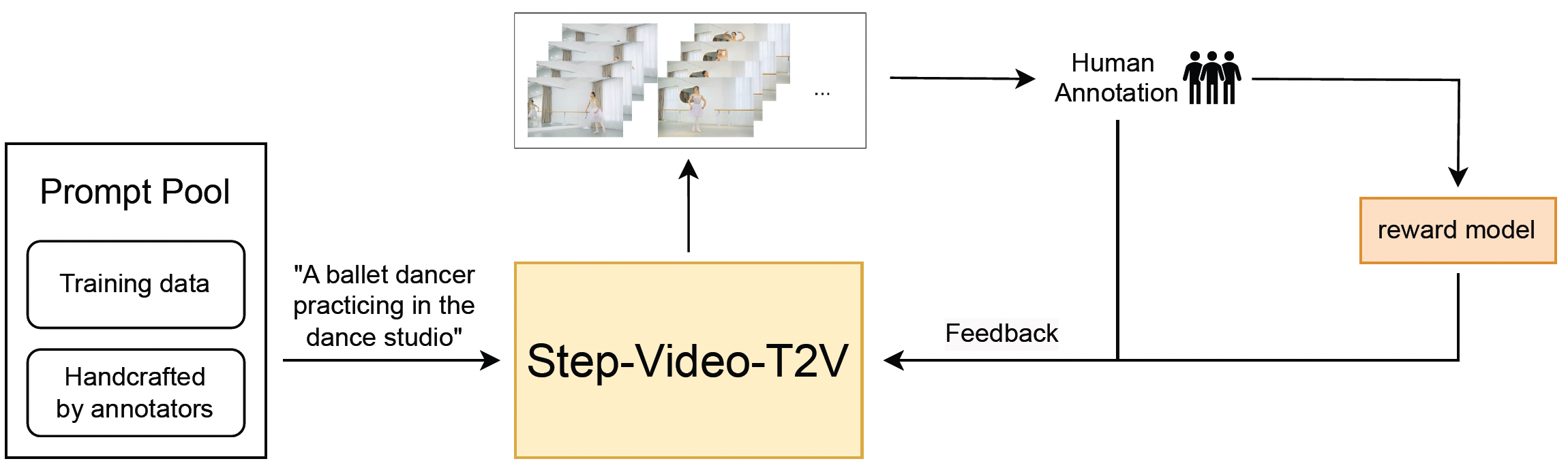
|
|
|
|
|
|
|
|
Project: Flow-RAR, Flow-DPO
Authors: Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Menghan Xia, Xintao Wang, Xiaohong Liu, Fei Yang, Pengfei Wan, Di Zhang, Kun Gai, Yujiu Yang, Wanli Ouyang
Organizations: CUHK, Tsinghua University, Kuaishou Technology, Shanghai Jiao Tong University, Shanghai AI Lab
Summary: A human preference video dataset; Adapt diffusion-based reinforcement learning to flow-based video generation models.
Project: PARM
Authors: Ziyu Guo, Renrui Zhang, Chengzhuo Tong, Zhizheng Zhao, Peng Gao, Hongsheng Li, Pheng-Ann Heng
Organizations: CUHK, Peking University, Shanghai AI Lab
Summary: Apply Chain-of-Thought into image generation and combine it with reinforcement learning to further improve performance.
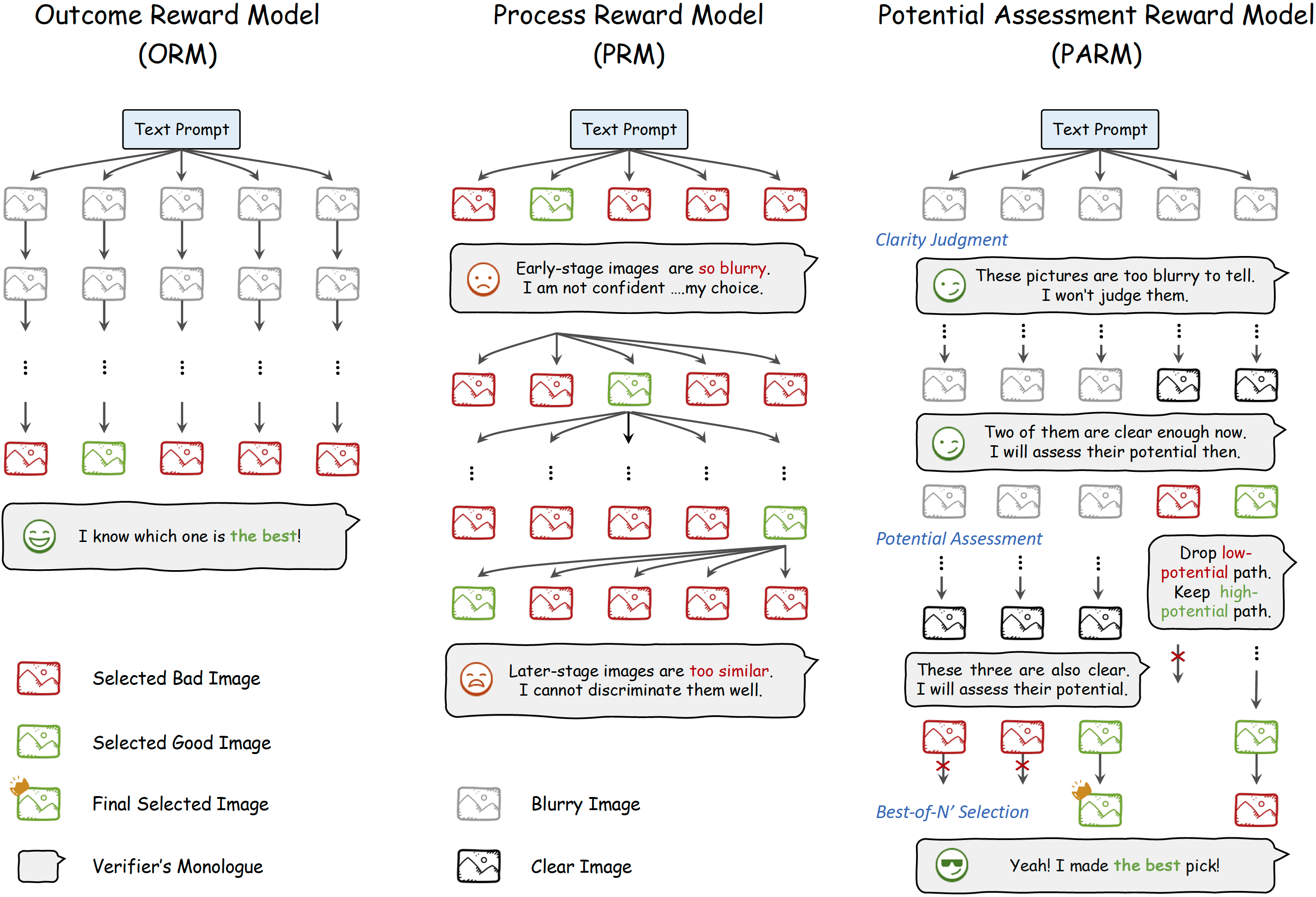
|
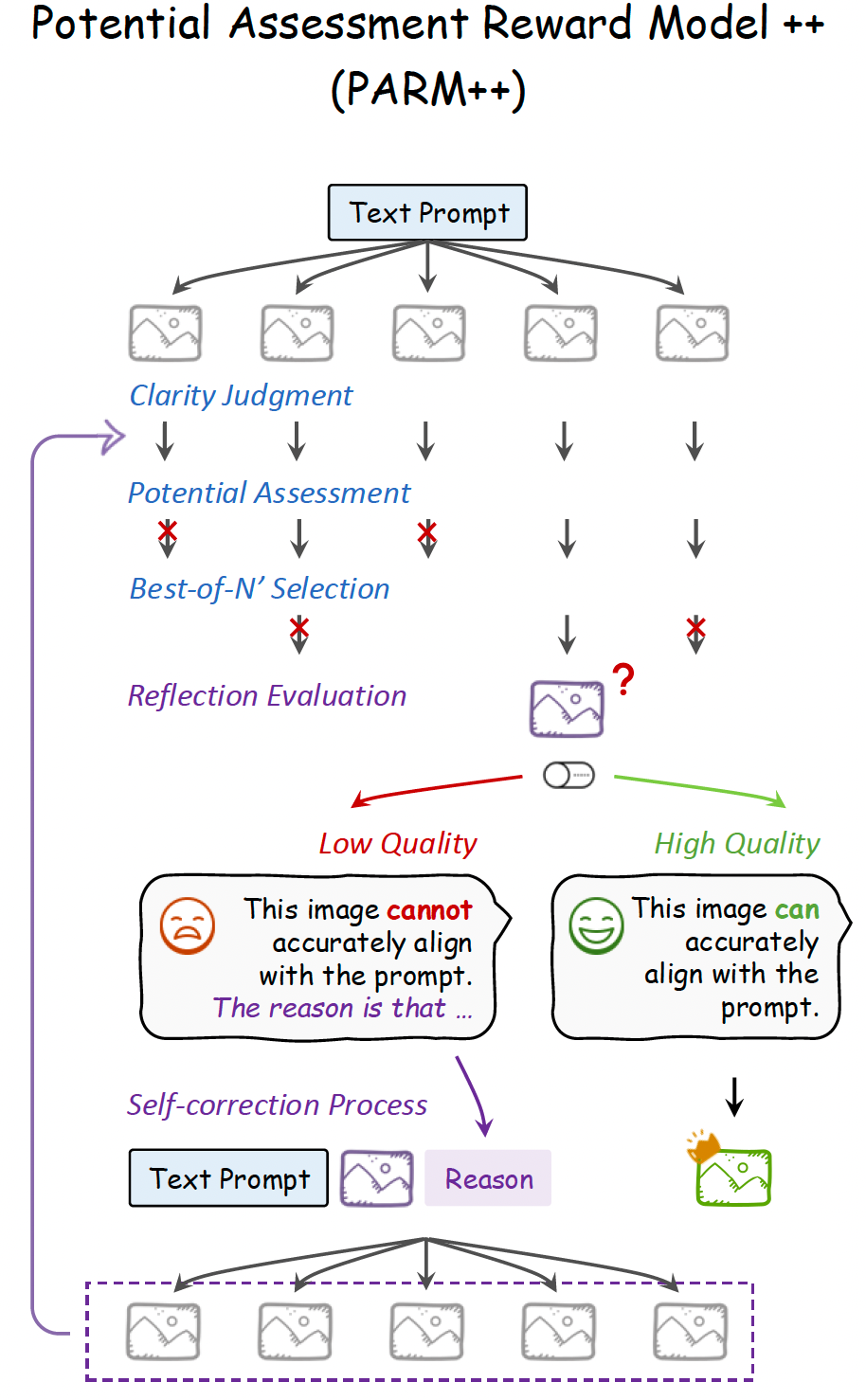
|
Project: Scaling Analysis
Authors: Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, Saining Xie
Organizations: NYU, MIT, Google
Summary: Analysis on inference-time scaling of diffusion models for image generation from the axes of verifiers and algorithms.
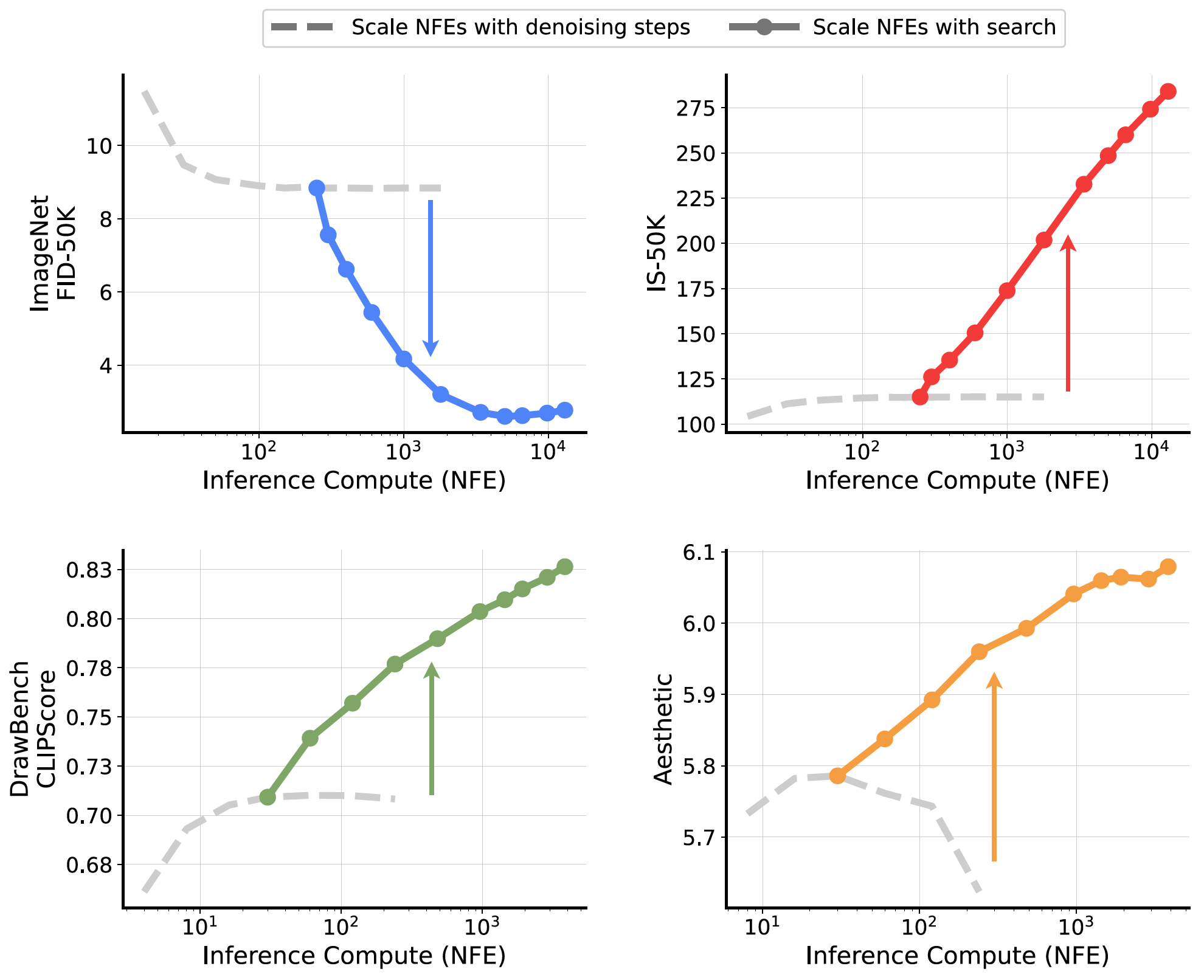
|
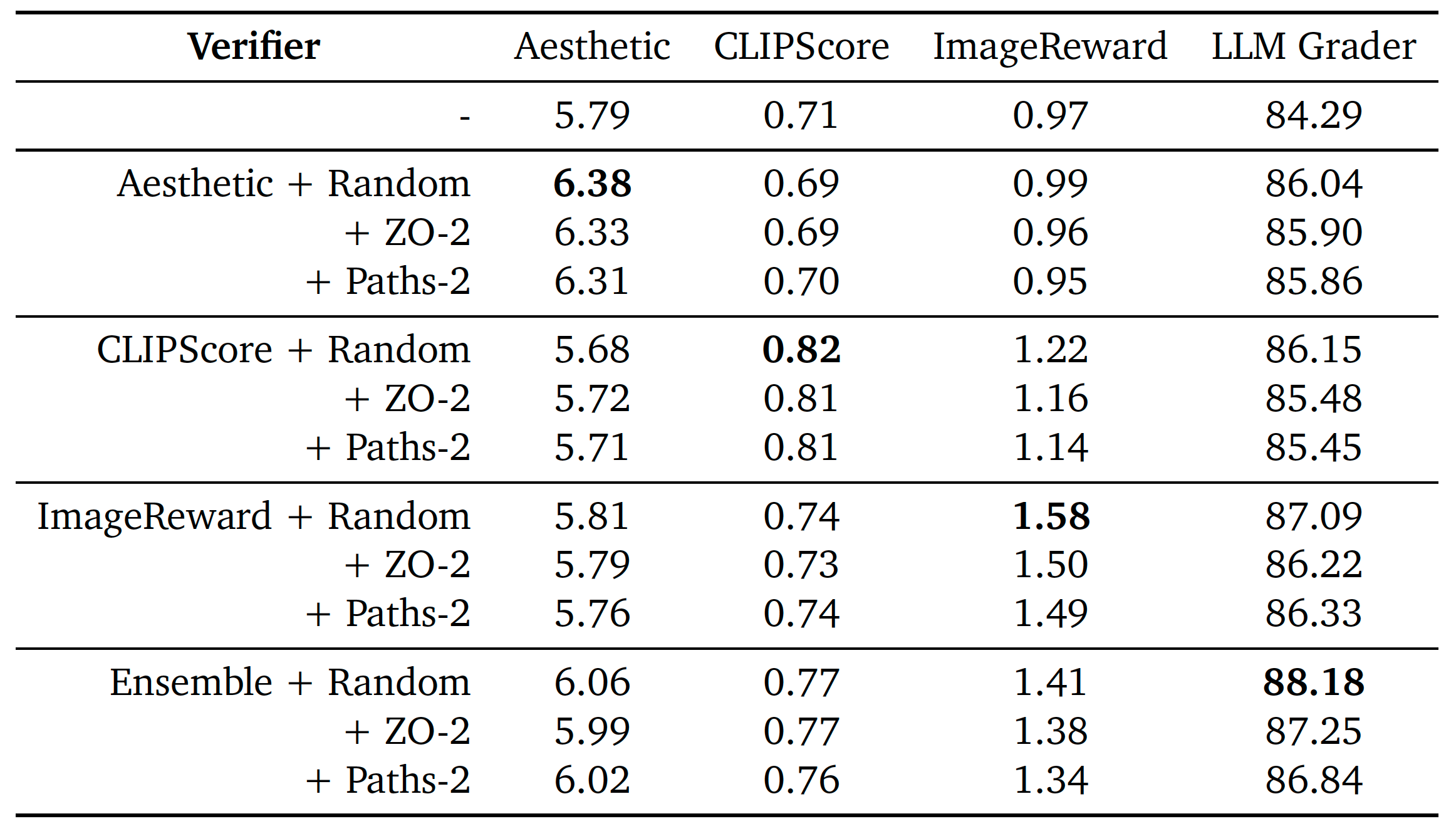
|
Project: FGA-BLIP2
Authors: Shuhao Han, Haotian Fan, Jiachen Fu, Liang Li, Tao Li, Junhui Cui, Yunqiu Wang, Yang Tai, Jingwei Sun, Chunle Guo, Chongyi Li
Organizations: Nankai University, ByteDance Inc, NKIARI
Summary: Use 40K image-text pairs with fine-grained human annotations for image generation evaluation.
Project: Sampling
Authors: Lichen Bai, Shitong Shao, Zikai Zhou, Zipeng Qi, Zhiqiang Xu, Haoyi Xiong, Zeke Xie
Organizations: The Hong Kong University of Science and Technology (Guangzhou), Mohamed bin Zayed University of Artificial Intelligence, Baidu Inc
Summary: Use guidance gap between denosing and inversion and iteratively perform them to improve image generation quality.

|
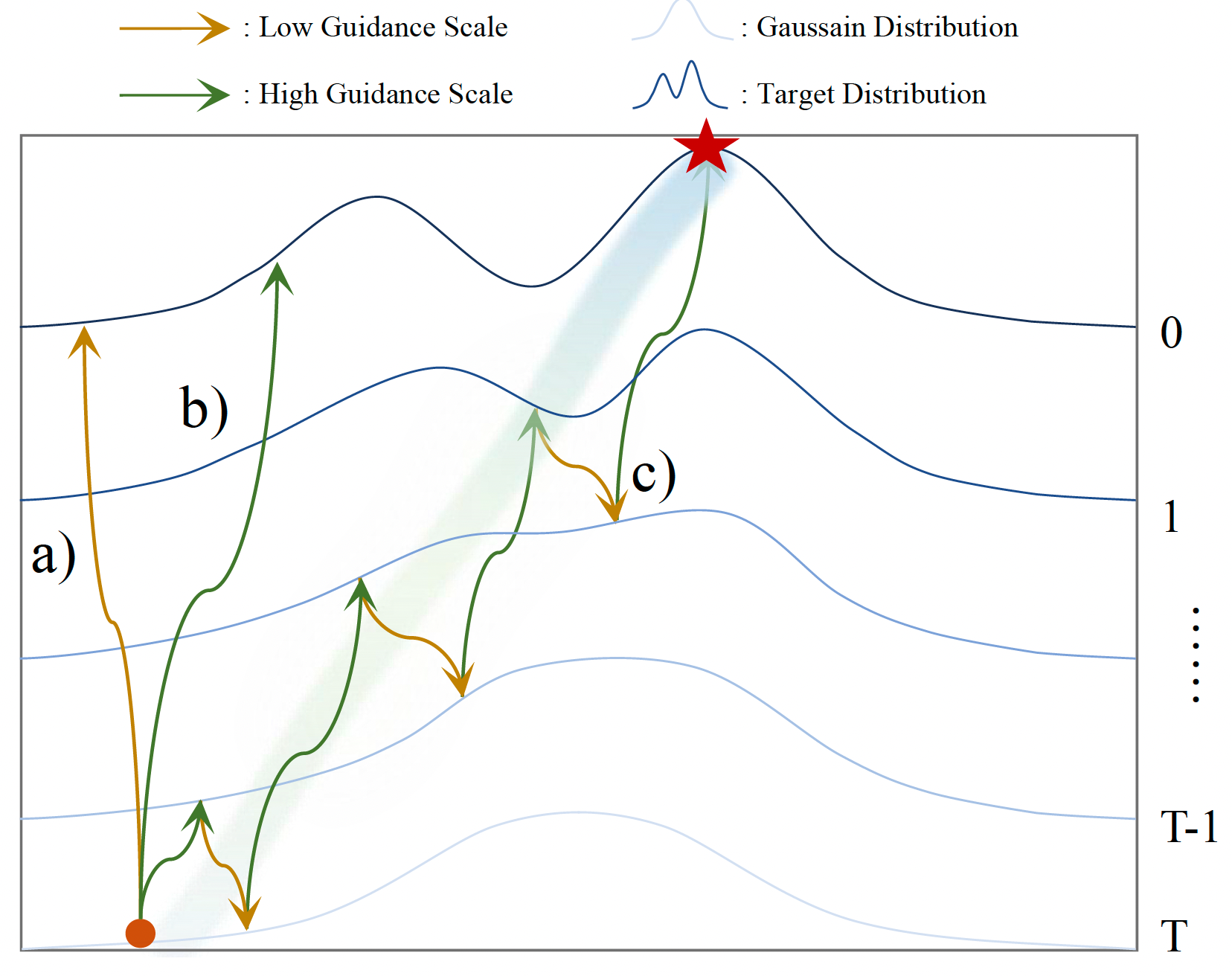
|
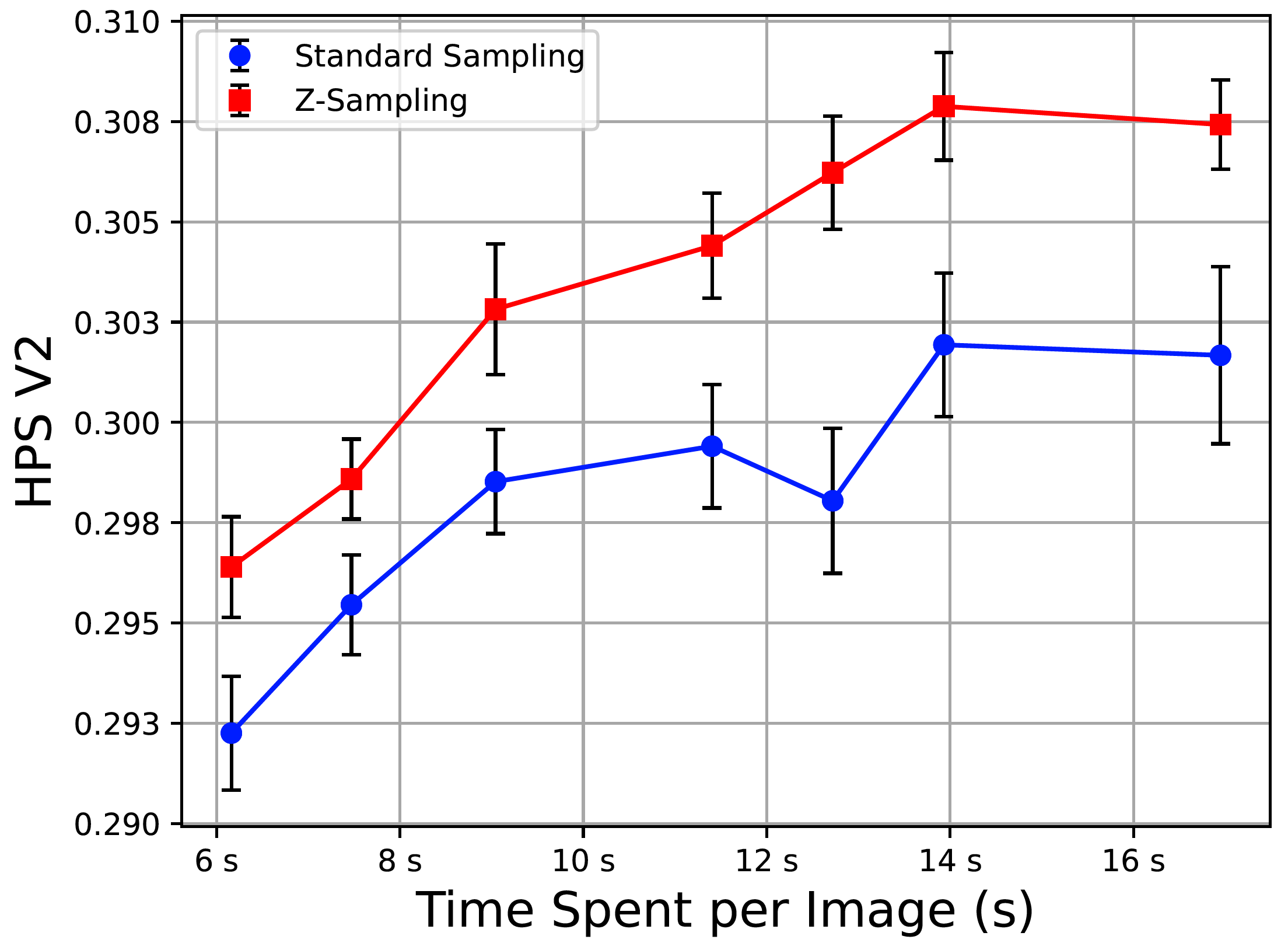
|
Project: Flow Matchiing Guide and Code
Authors: Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, Itai Gat
Organizations: FAIR at Meta, MIT CSAIL, Weizmann Institute of Science
Summary: Comprehensive and self-contained review of the flow matching algorithm, covering its mathmatical foundations, design choices, extensions, and code implementations.
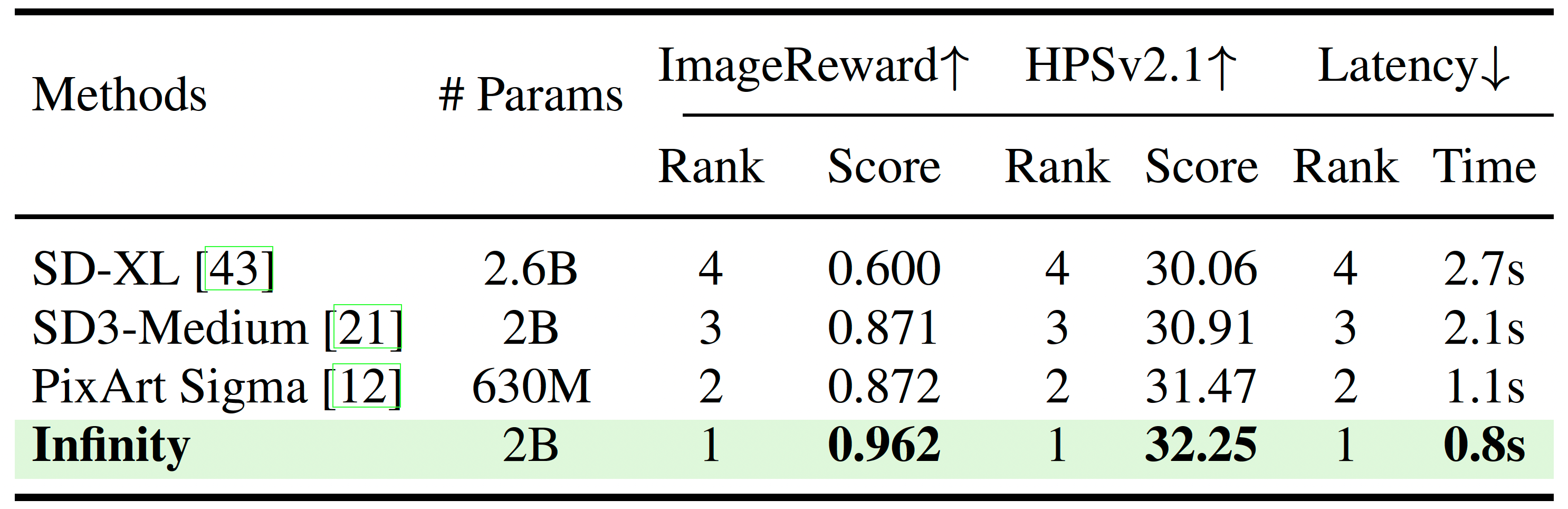
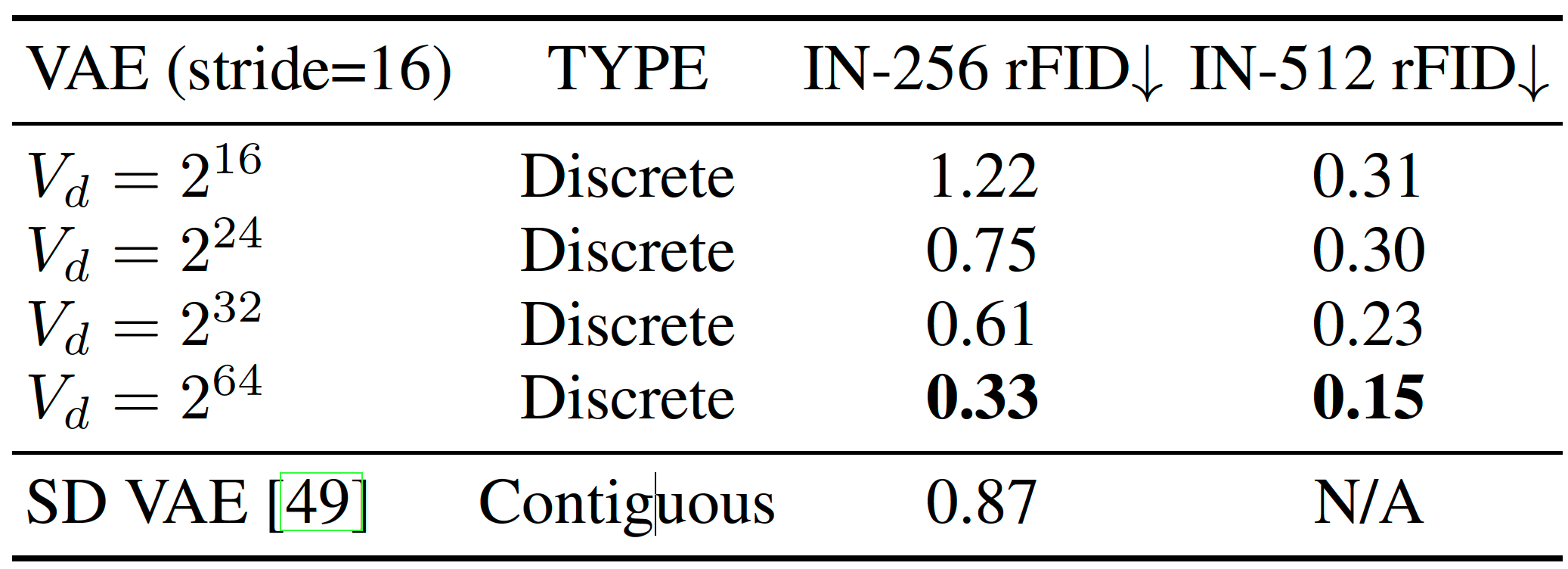
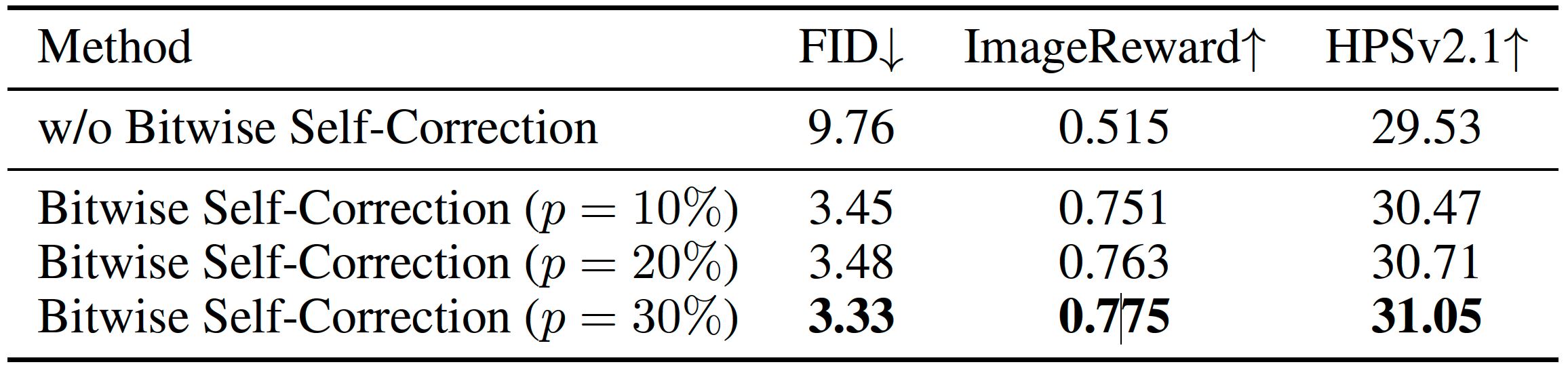
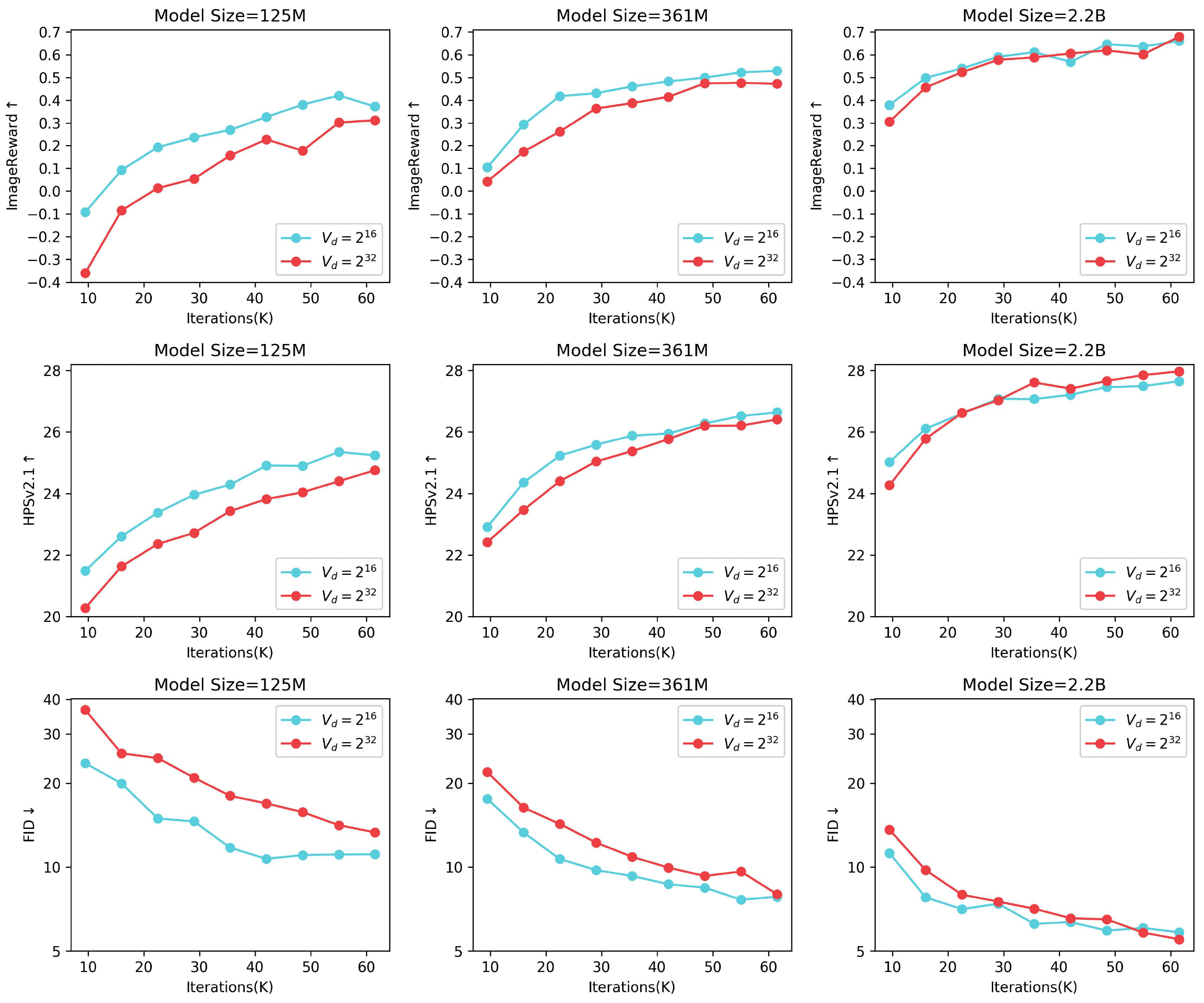
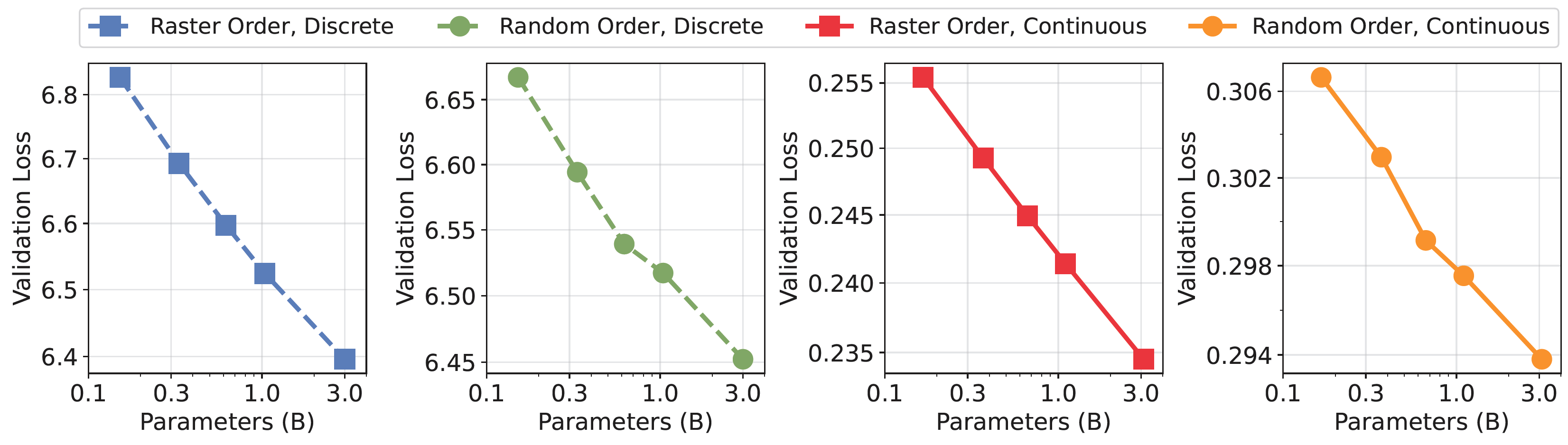
Project: Infinity
Authors: Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, Xiaobing Liu
Organizations: ByteDance
Summary: It improves VAR by applying bitwise modeling that makes vocabulary "infinity" to open up new posibilities of discrete text-to-image generation with next-scale prediction paradigm.
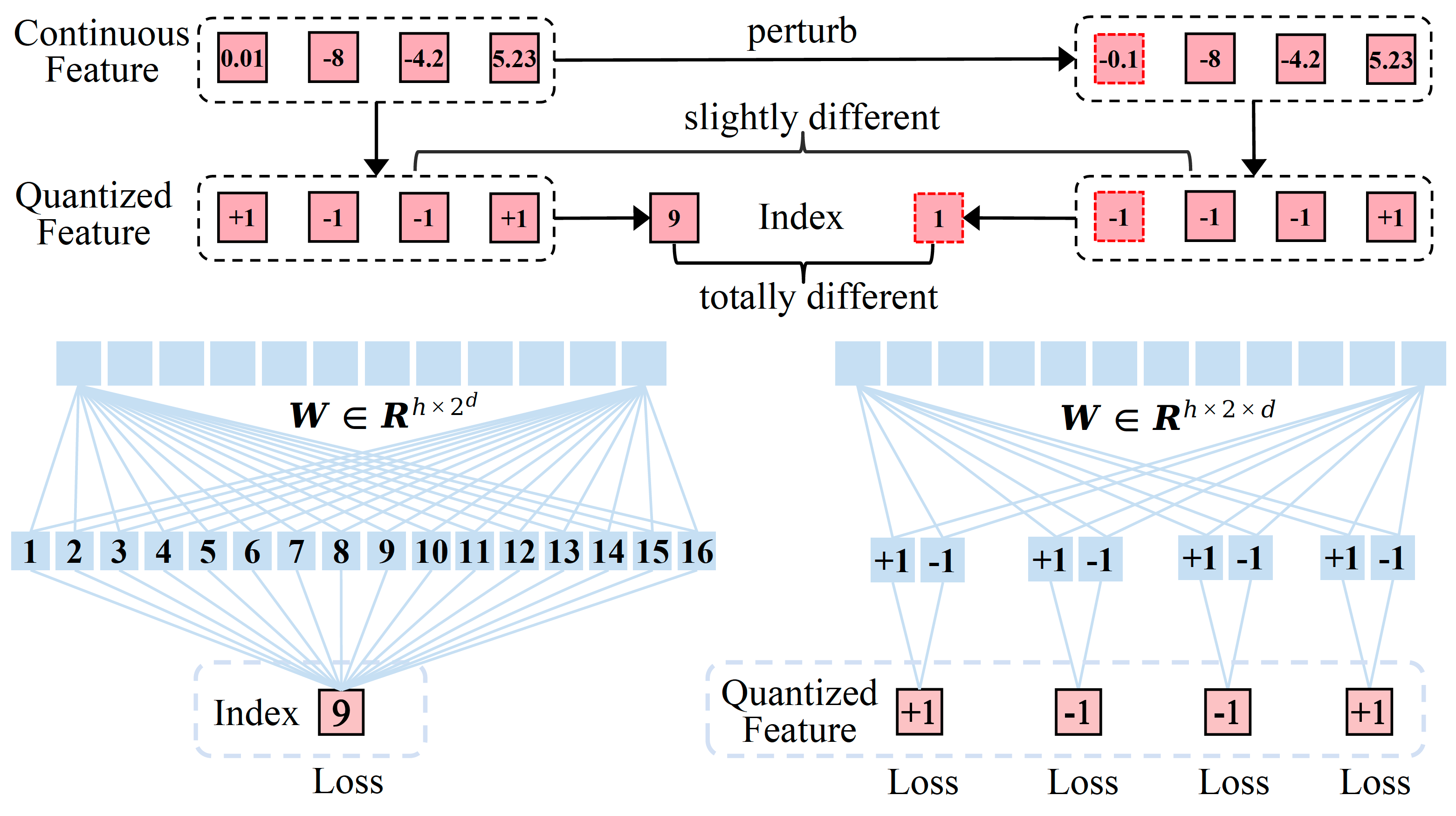
|
|
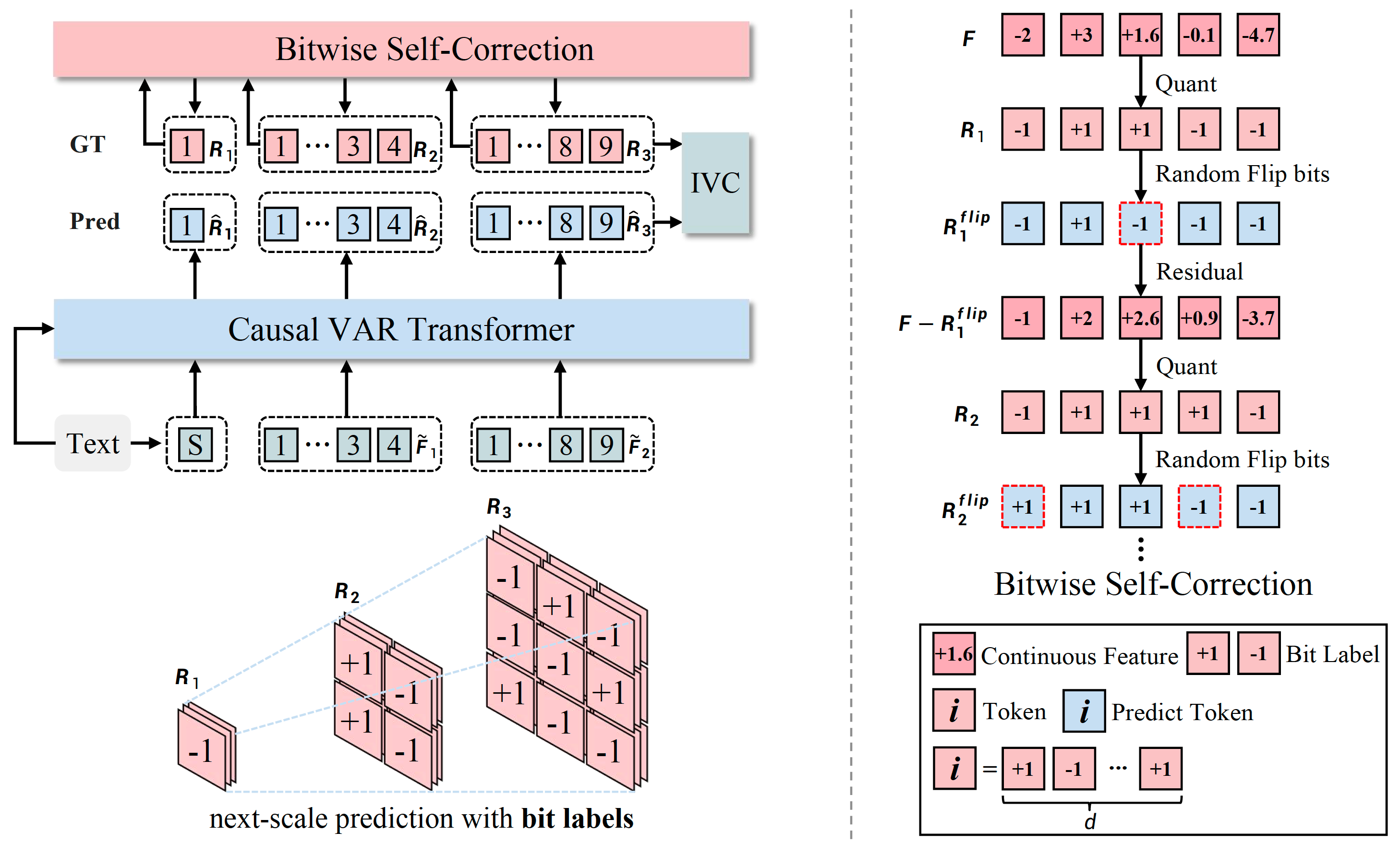
|
|
|
|

|
|
|
|
|
|
|
|
Project: HunyuanVideo
Authors: Hunyuan Foundation Model Team
Organizations: Tencent
Summary: Tencent (Hunyuan Team)'s open-sourced video generation model (13B) using diffusion transformer and conducting fine-grained data curation, captioning, and training scaling.
Project: Reliable-Seed
Authors: Shuangqi Li, Hieu Le, Jingyi Xu, Mathieu Salzmann
Organizations: EPFL, Stony Brook University
Summary: The noises initialized by reliable seeds result in accurate image generation such as numeracy and position, and use these generated data for fine-tuning further improves performance.
Project: MovieGen
Authors: Adam Polyak et al.
Organizations: Meta
Summary: A diffusion transformer-based model (30B) for 16s / 1080p / 16 fps video and synchronized audio generation.
Project: Fluid
Authors: Lijie Fan, Tianhong Li, Siyang Qin, Yuanzhen Li, Chen Sun, Michael Rubinstein, Deqing Sun, Kaiming He, Yonglong Tian
Organizations: Google DeepMind, MIT
Summary: It shows auto-regressive models with continuous tokens beat discrete tokens counterpart, and some interesting empirical observations during scaling progress.
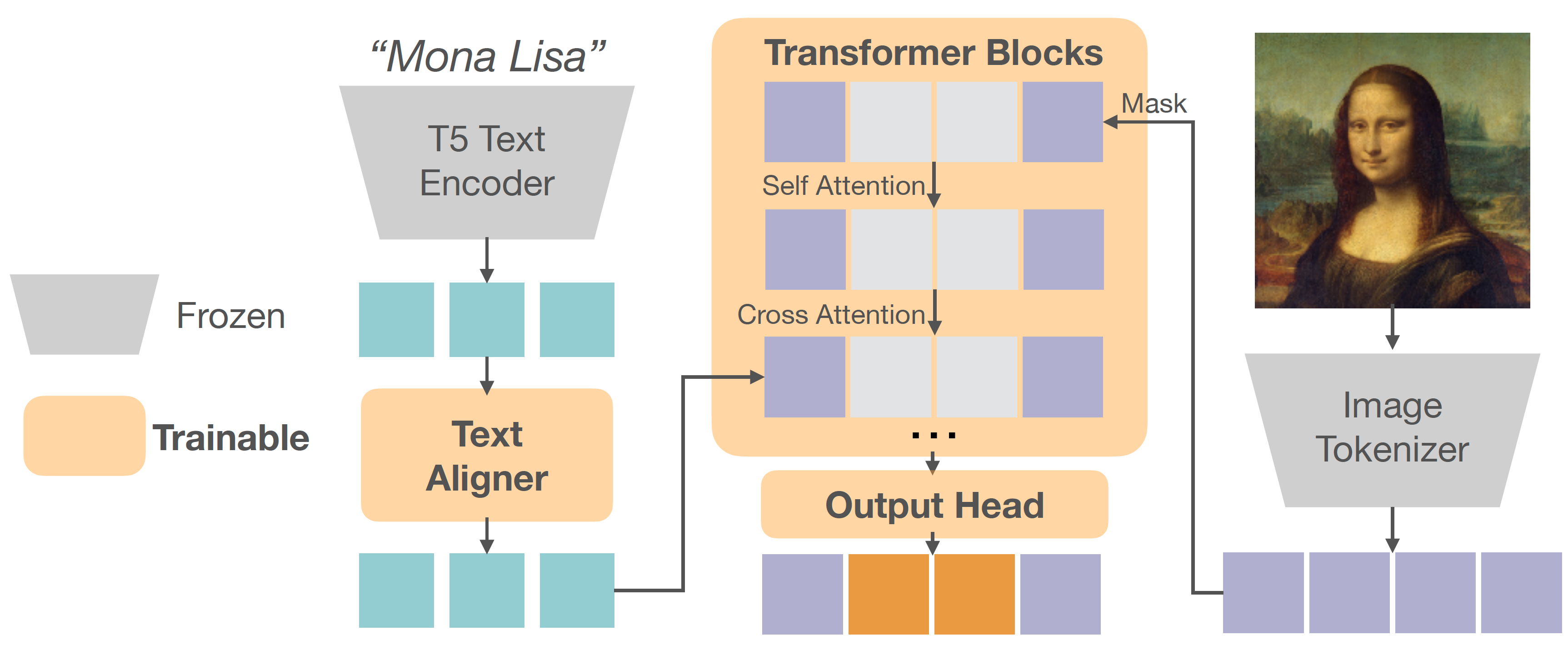
Text tokenizer: text (max length 128) is converted to discrete tokens using T5-XXL. Model structure: transformer with cross-attention attending to text embedding. Decoder: text: softmax with cross-entropy loss; image: MLP with diffusion loss. |
|
|
|
|
|
|
|
|
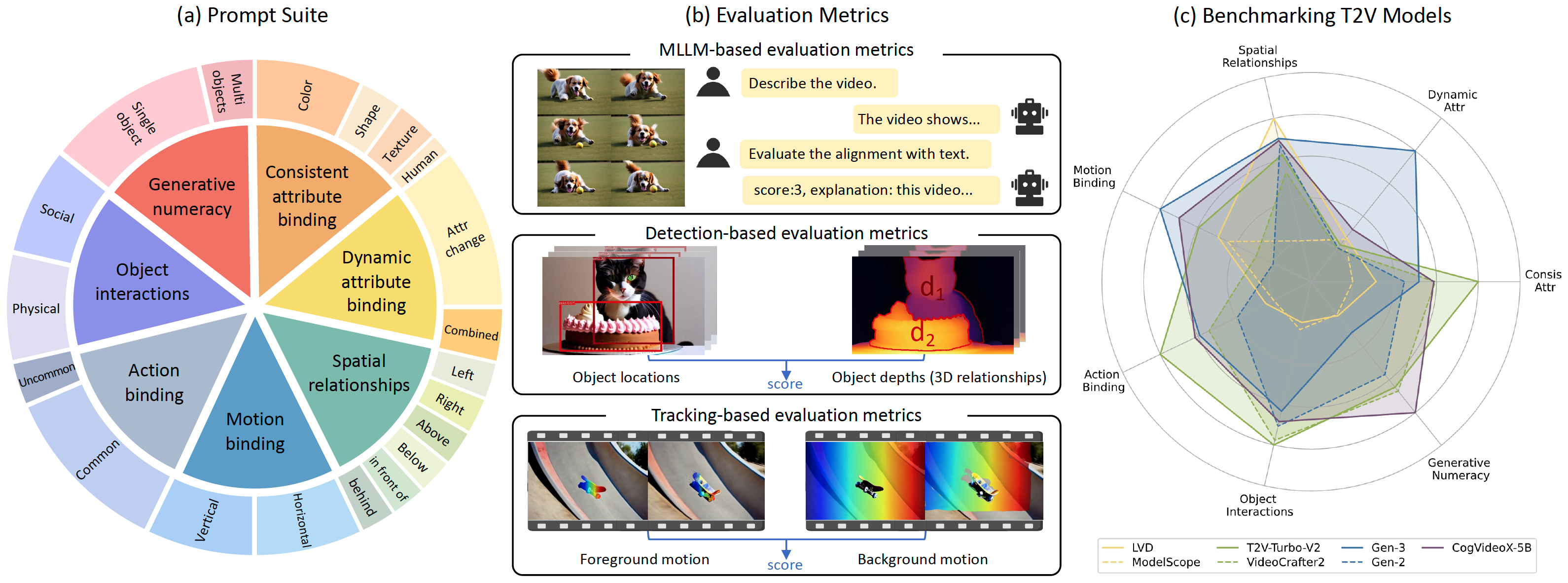
Project: T2V-CompBench
Authors: Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, Xihui Liu
Organizations: The University of Hong Kong, The Chinese University of Hong Kon, Huawei Noah's Ark Lab
Summary: Use 1400 prompts to evaluate video generation on compositional generation, including consistent attribute binding, dynamic attribute binding, sptial relationships, motion binding, action binding, object interations, generative numeracy.
|
Project: DiT-MoE
Authors: Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Junshi Huang
Organizations: Kunlun Inc.
Summary: A diffusion transformer (16B) with MoE that inserts experts into DiT blocks for image generation.
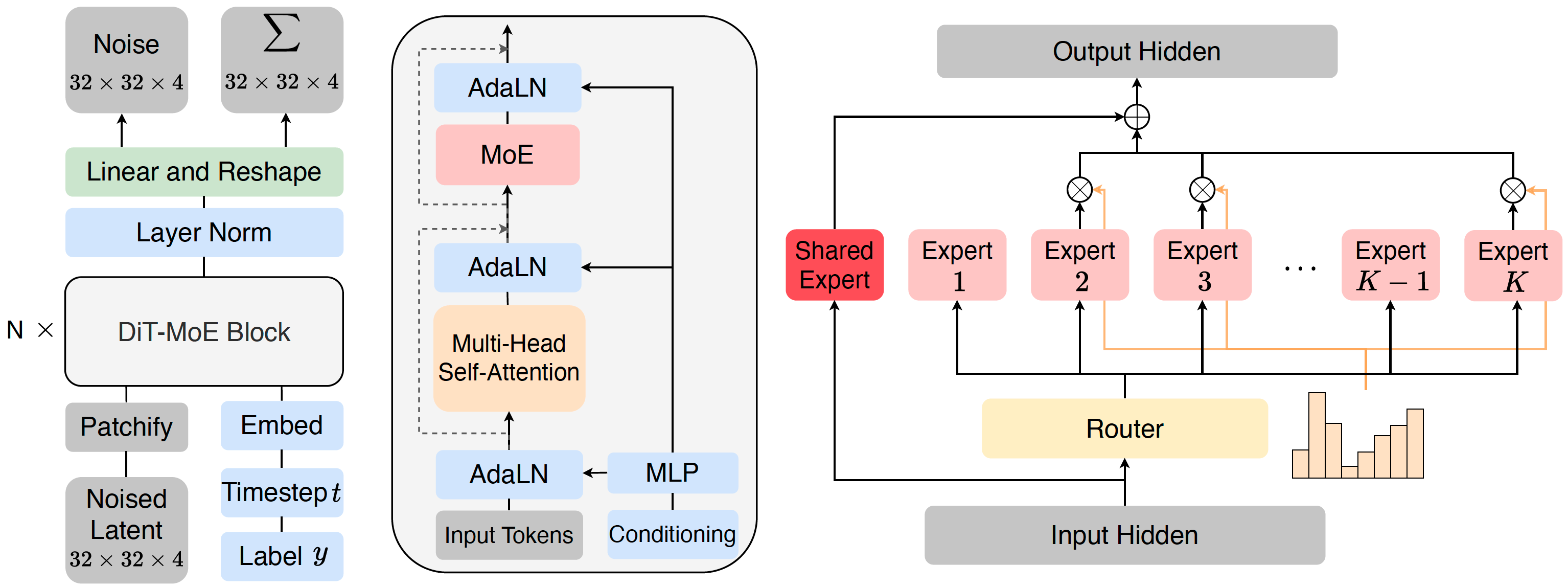
|
Project: LlamaGen
Authors: Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, Zehuan Yuan
Organizations: The University of Hong Kong, ByteDance
Summary: Show that applying "next-token prediction" to vanilla autoregressive models achieves good class-conditional & text-conditional image generation performance.
Project: MPS
Authors: Sixian Zhang, Bohan Wang, Junqiang Wu, Yan Li, Tingting Gao, Di Zhang, Zhongyuan Wang
Organizations: Kuaishou Technology
Summary: Apply condition upon CLIP to learn multi-dimensional preference score: aesthetics & alignment & detail & overall, trained on a dataset with 92K preference choices of 61K images.
Project: VAR
Authors: Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang
Organizations: Peking University, Bytedance Inc
Summary: Employ next-scale prediction to make auto-regressive models surpass diffusion transformers for image generation on image quality, inference speed, data efficiency, scalability.
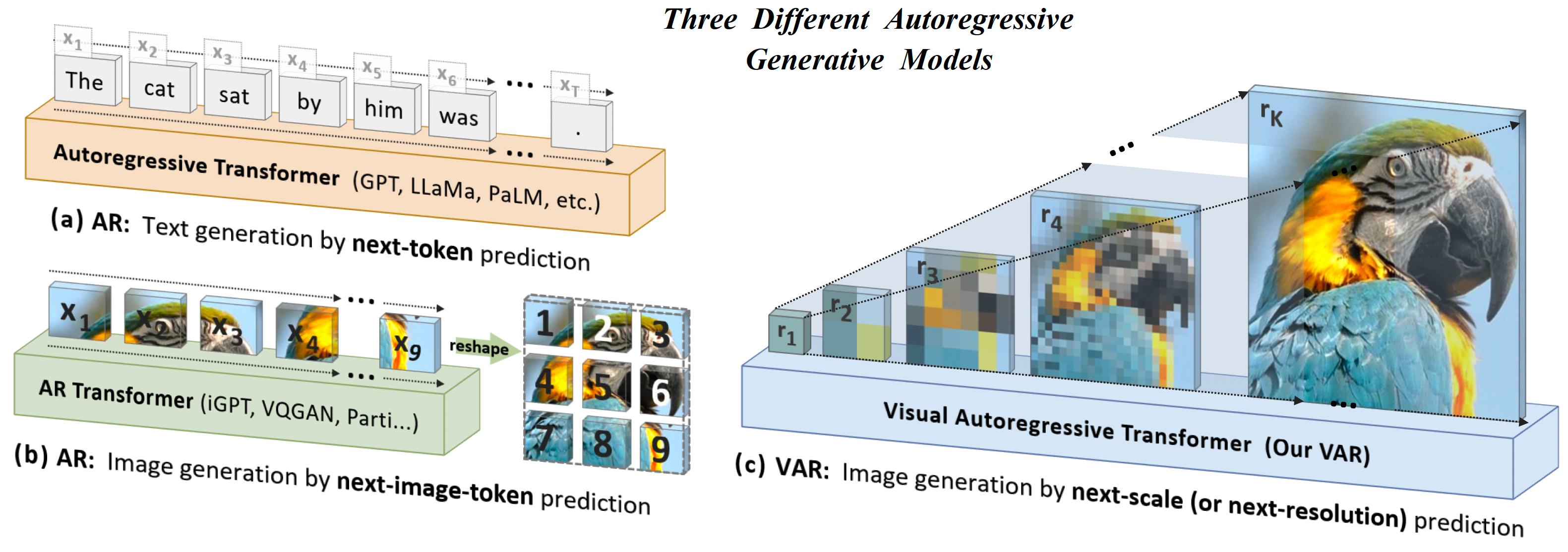
|
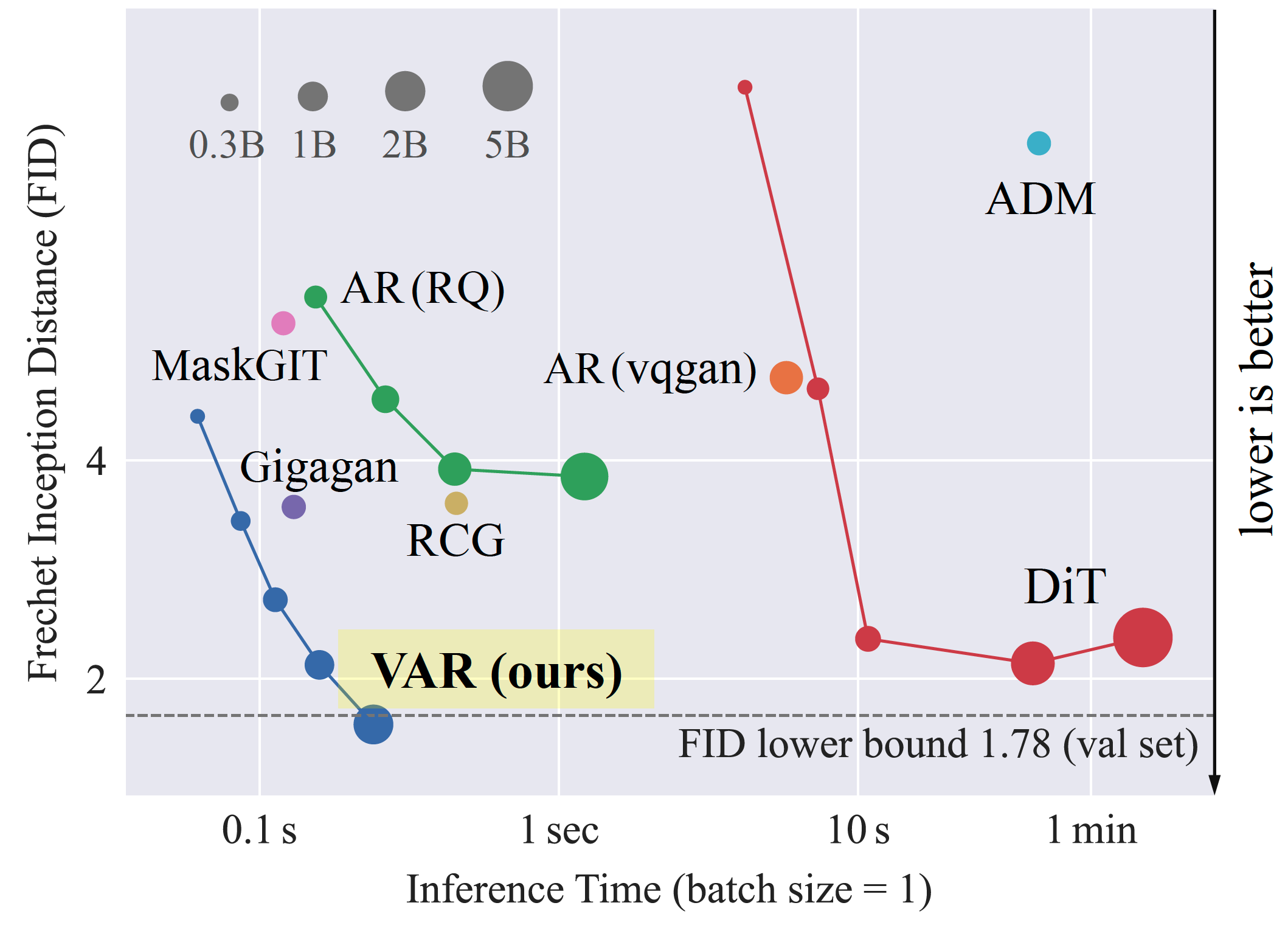
|
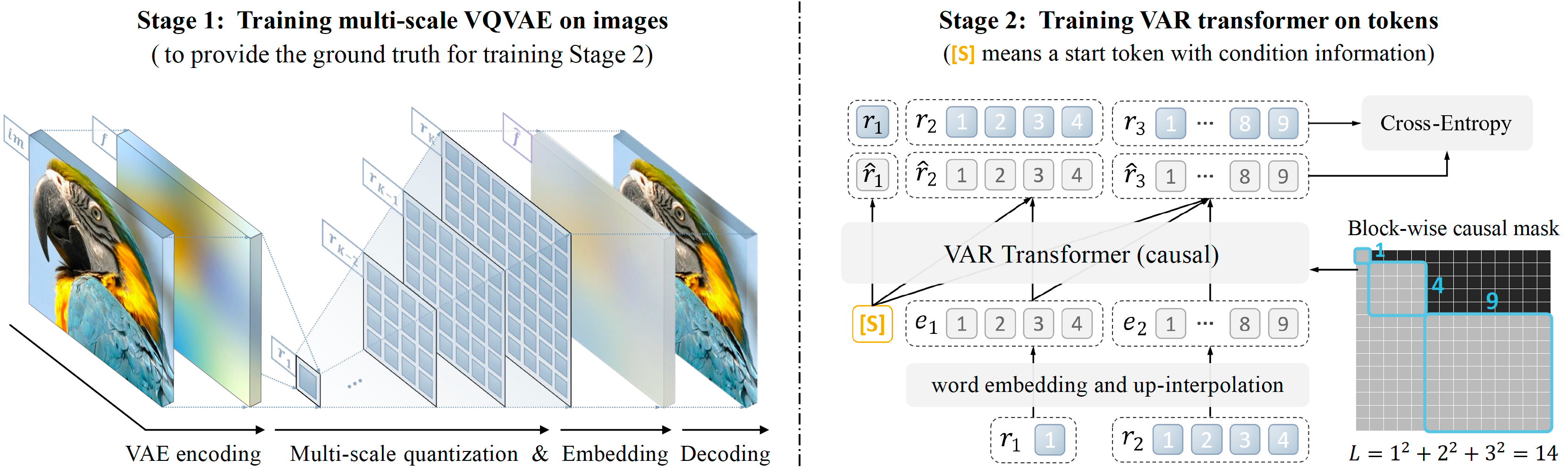
|

|
Project: VQAScore
Authors: Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, Deva Ramanan
Organizations: Crnegie Mellon University, Meta
Summary: VQAScore: alignment probability of "yes" answer from a VQA model with CLIP-FlanT5 structure; GenAI-Bench: evaluation benchmark with 1600 prompts for image generation.
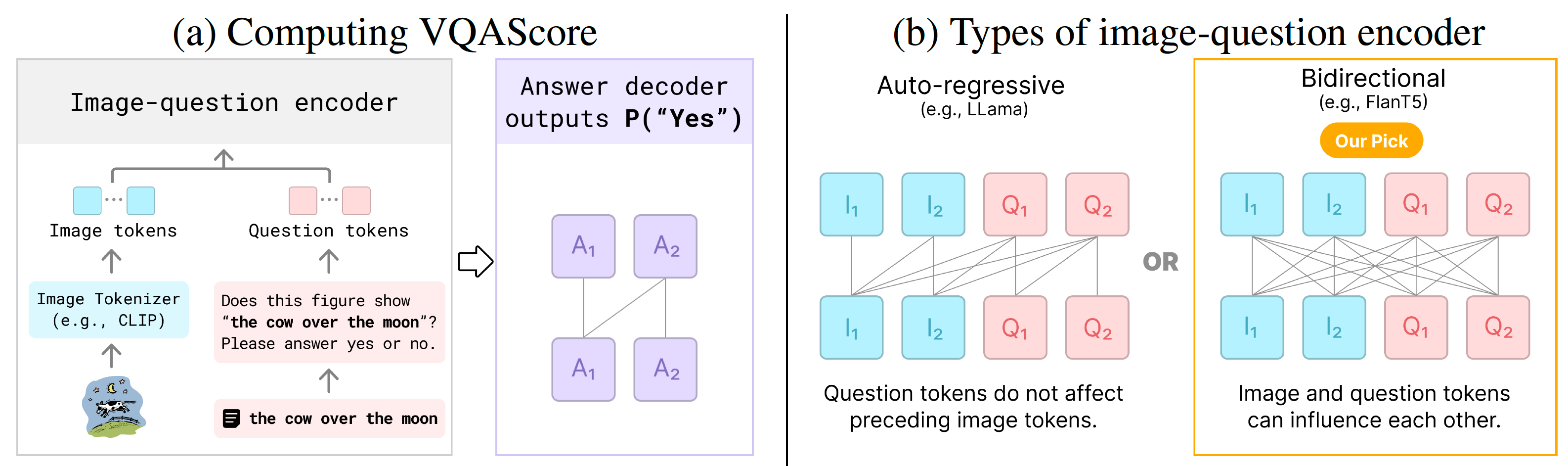
|
Project: SD3-Turbo
Authors: Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, Robin Rombach
Organizations: Stability AI
Summary: Perform distillation of diffusion models in latent space using teacher-synthetic data and optimizing only an adversarial loss with the teacher as the discriminator.
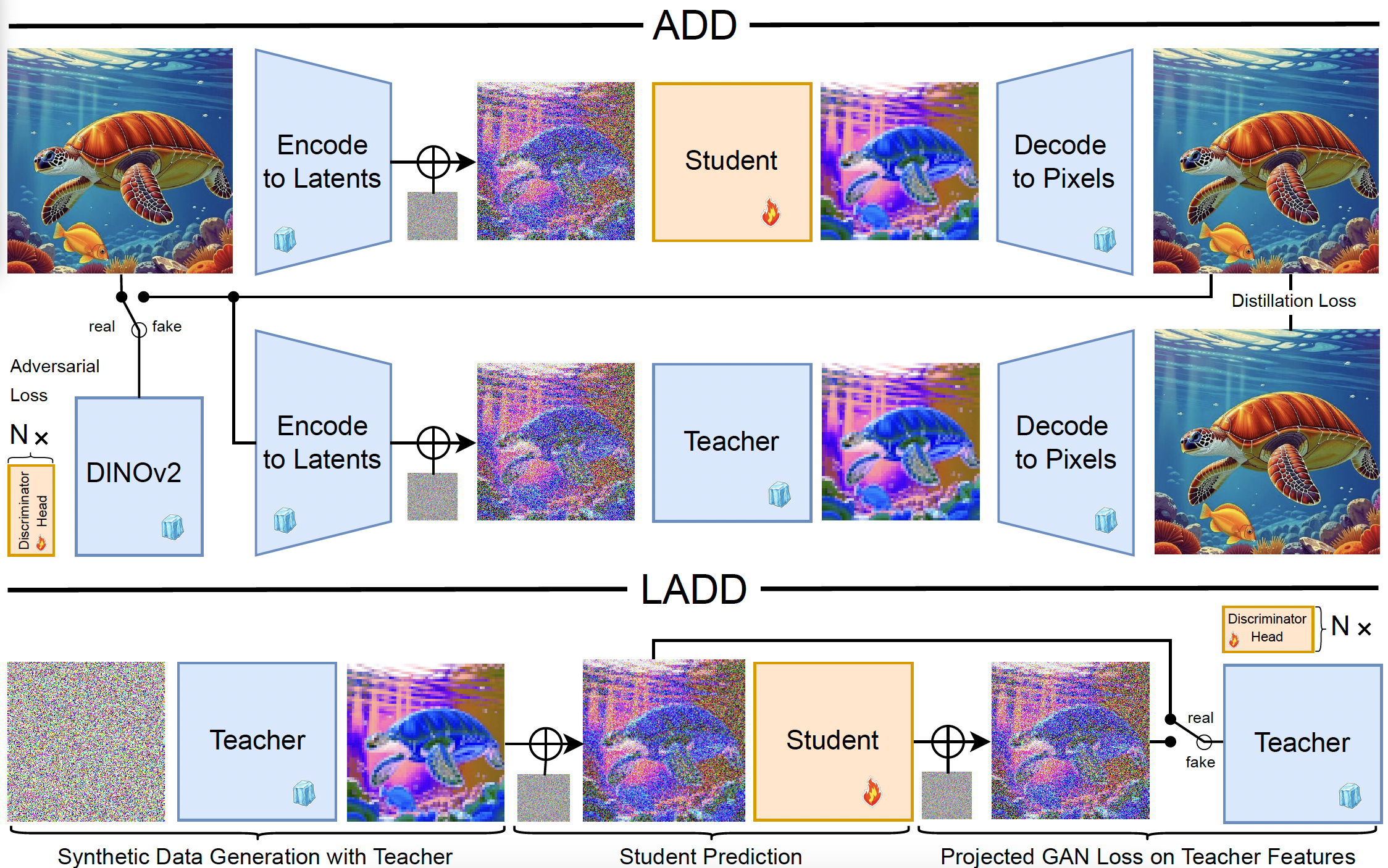
LADD: (1) Use teacher generated images instead of real images for distillation; (2) Use teacher as the discrinimator. Advantages: (1) Save memory and improve efficiency; (2) Diffusion model teacher as the discriminator provides noise-level feedback; (3) Diffusion model as the discriminator handles multi-aspect ratio; (4) Diffusion model as the discriminator aligns with human perception on shape. |

|

|
|

|
Project: DPG-Bench
Authors: Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, Gang Yu
Organizations: Tencent
Summary: ELLA: Replace CLIP with LLM to understand dense prompts; DPG-Bench: evaluate image generation on dense prompts.
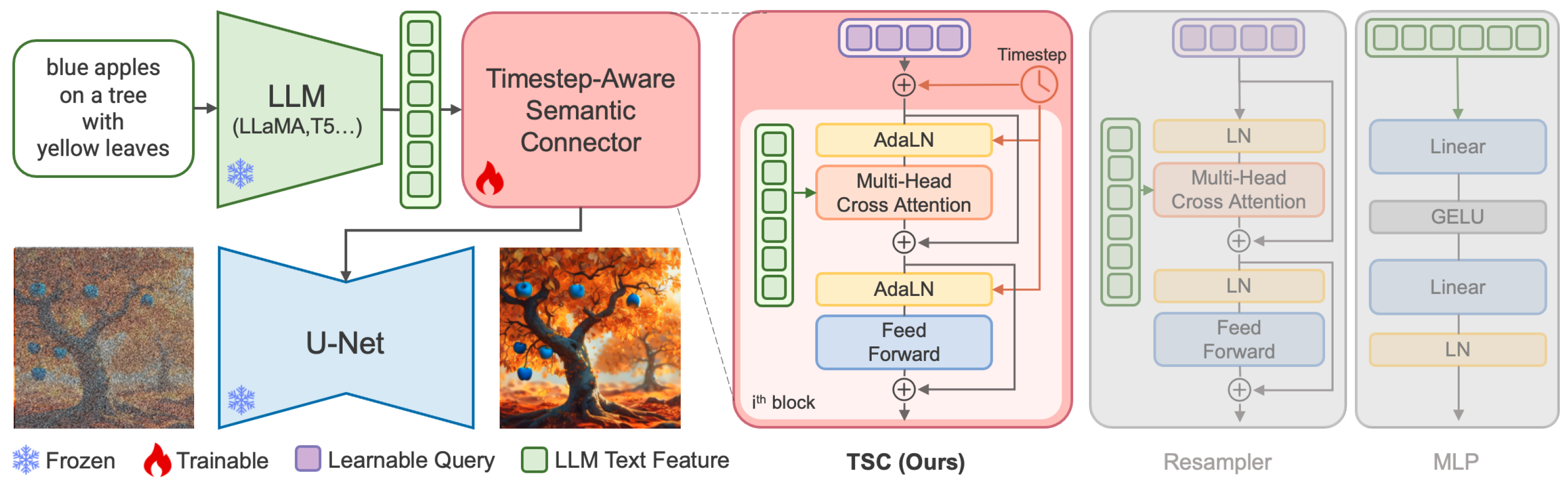
|
Project: InstructVideo
Authors: Hangjie Yuan, Shiwei Zhang, Xiang Wang, Yujie Wei, Tao Feng, Yining Pan, Yingya Zhang, Ziwei Liu, Samuel Albanie, Dong Ni
Organizations: Zhejiang University, Alibaba Group, Tsinghua University, Singapore University of Technology and Design, Nanyang Technological University, University of Cambridge
Summary: Use HPS v2 to provide reward and train video generation models in an editing manner.
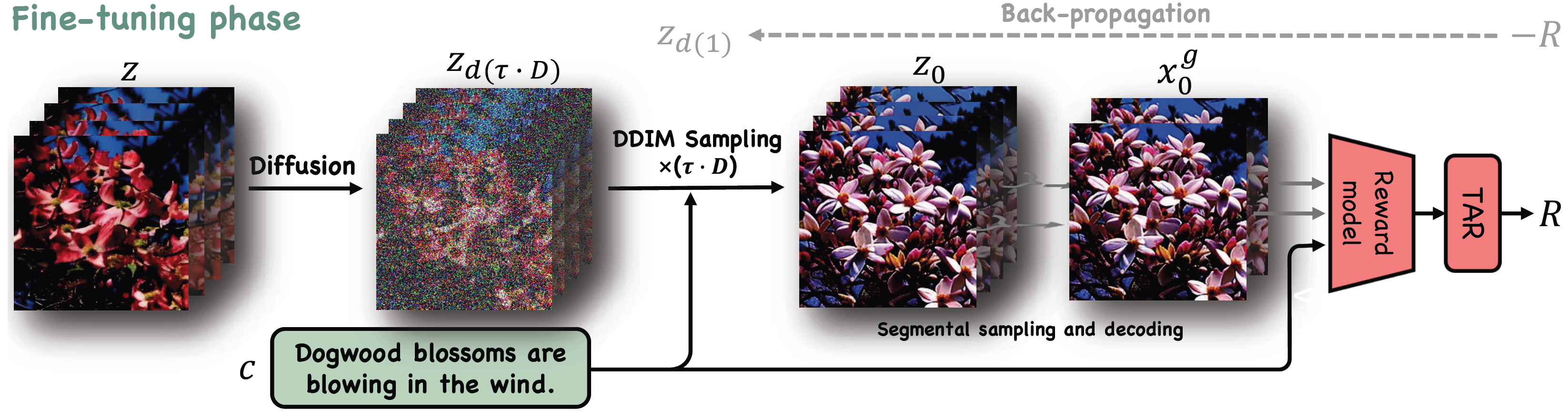
|
Project: Diffusion-DPO
Authors: Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, Nikhil Naik
Organizations: Nikhil Naik, Salesforce AI, Stanford University
Summary: Adapt Direct Preference Optimization (DPO) from large language models to diffusion models for image generation.
Project: VBench
Authors: Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
Organizations: Nanyang Technological University, Shanghai Artificial Intelligence Laboratory, The Chinese University of Hong Kong, Nanjing University
Summary: Evaluate video generation from 16 dimensions within the perspectives of video quality and video-prompt consistency.
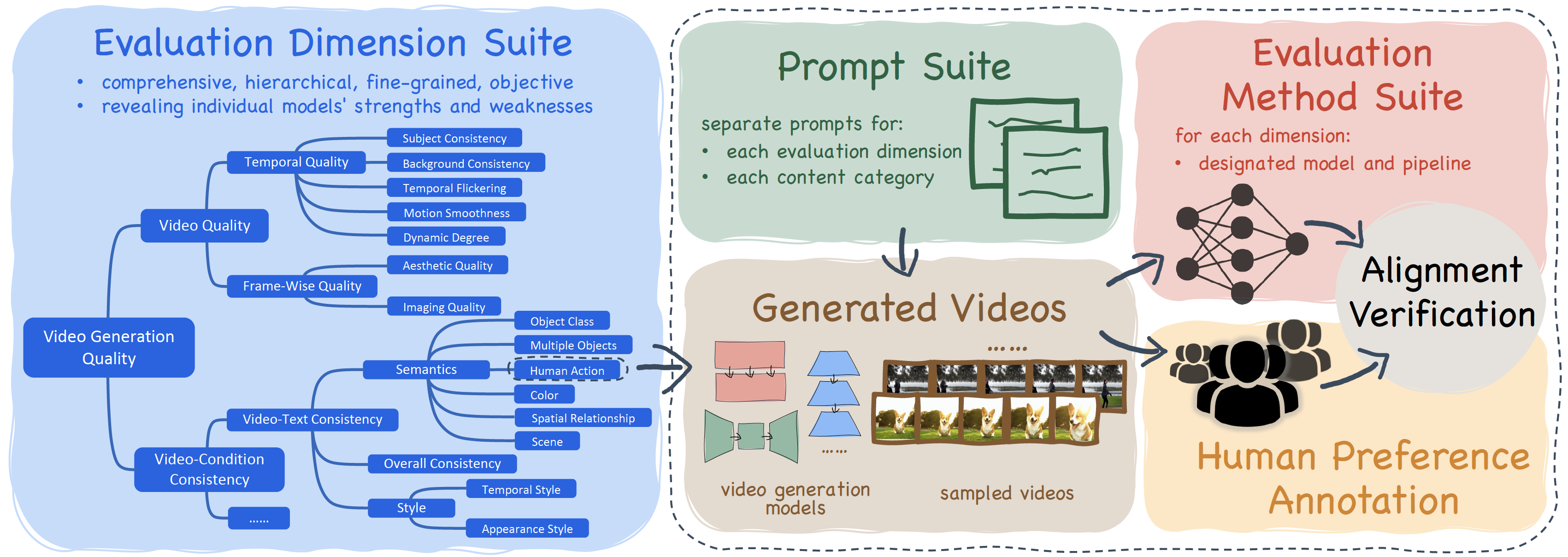
|
Project: GenEval
Authors: Dhruba Ghosh, Hanna Hajishirzi, Ludwig Schmidt
Organizations: University of Washington, Allen Institute for AI, LAION
Summary: An object-focused framework for image generation evaluation by providing scores of single object, two objects, counting, colors, position, attribute binding, and overall.
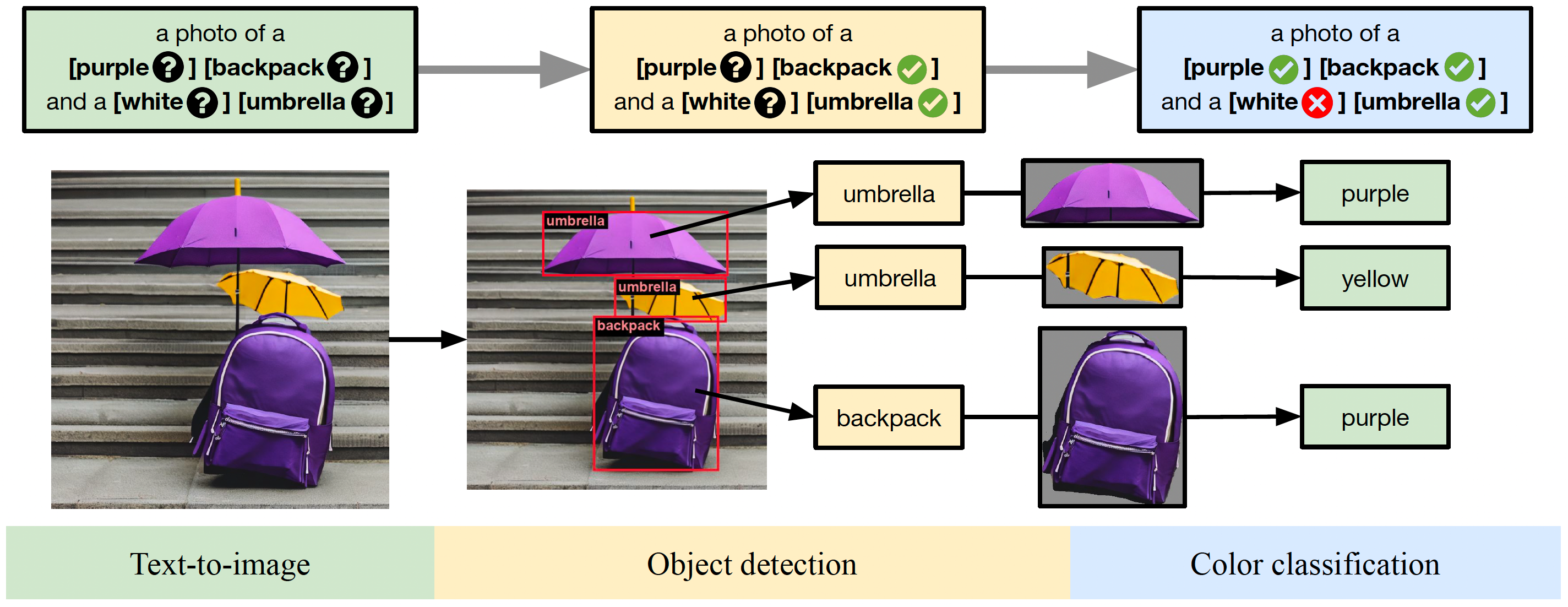
|
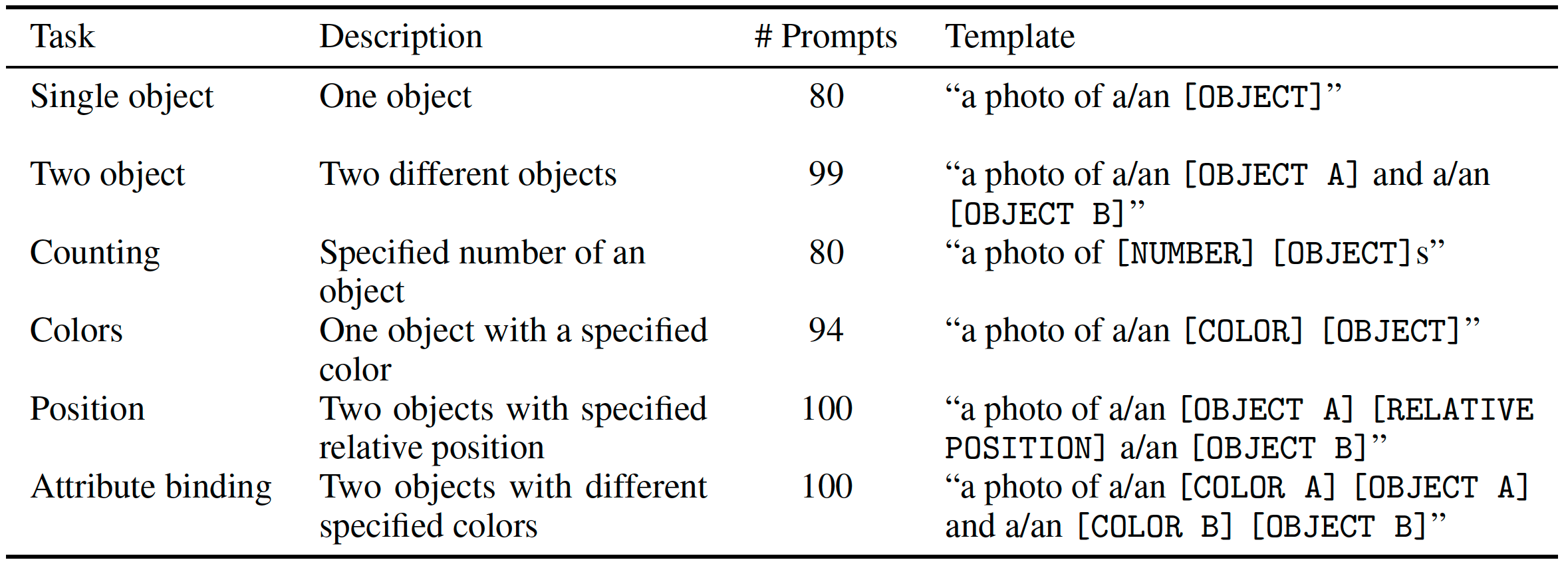
|
Project: T2I-CompBench
Authors: Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, Xihui Liu
Organizations: The University of Hong Kong, Huawei Noah's Ark Lab
Summary: Use 6000 prompts to train and evaluate image generation on compositional generation, including attribute binding, object relationship, and complex compositions.
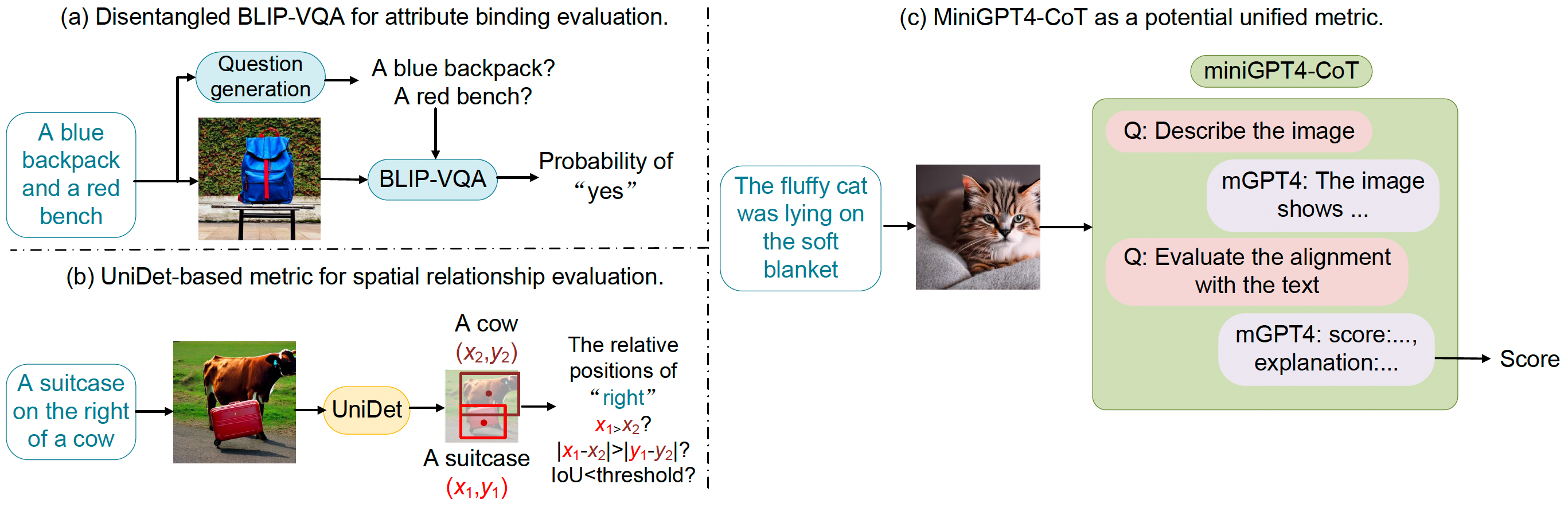
|
Project: SDXL
Authors: Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach
Organizations: Stability AI
Summary: Employ three times larger UNet backbone of SD, use resolution & crop coordinates & bucketing information as resolution condition for training, employ a refinement model.

(1) SDXL uses different transformer blocks compared to SD. (2) Use two text encoders OpenCLIP VIT-bigG & CLIP ViT-L. (3) The final model has 2.6B parameters with 817M parameters for text encoders. (4) Embeddings of height & width and cropping top & left and bucketing heigh & width are added to timestep embeddings. (5) Improve auto-encoder by employing larger batchsize of 256 and EMA. (6) Use a refiner of SDEdit for refining details. (7) Training: Stage 1: 256 x 256, 600K steps, batchsize 2048. Stage 2: 512 x 512, 200K steps. Stage 3: multi-aspect training. |
Project: HPS v2
Authors: Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, Hongsheng Li
Organizations: CUHK, SenseTime Research, Shanghai Jiao Tong University, Centre for Perceptual and Interactive Intelligence
Summary: HPD v2: 798K binary human preference choices on 433K pairs of generated images; HPS v2: use HPD v2 to fine-tune CLIP for image generation evaluation.
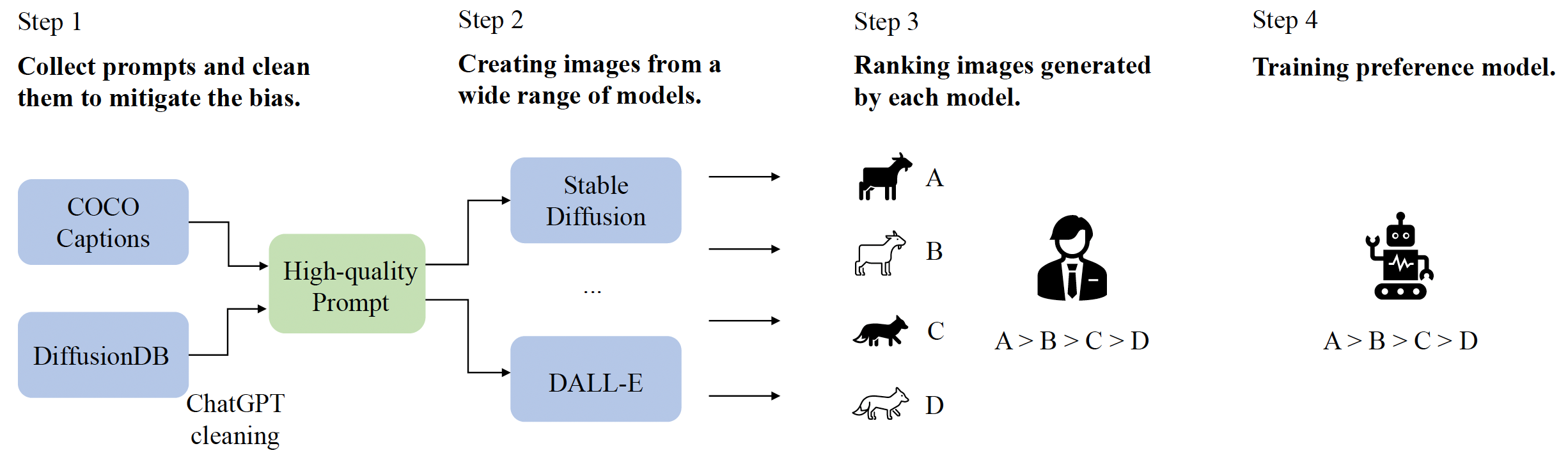
|
Project: PickScore
Authors: Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, Omer Levy
Organizations: Tel Aviv University, Stability AI
Summary: Pick-a-Pic: use a web app to collect user preferences; PickScore: train a CLIP-based model for image generation evaluation.
Project: ImageRewward
Authors: Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Organizations: Tsinghua University, Zhipu AI, Beijing University of Posts and Telecommunications
Summary: Train BLIP on 137K human preference image pairs for image generation and use it to tune diffusion models by Reward Feedback Learning (ReFL).
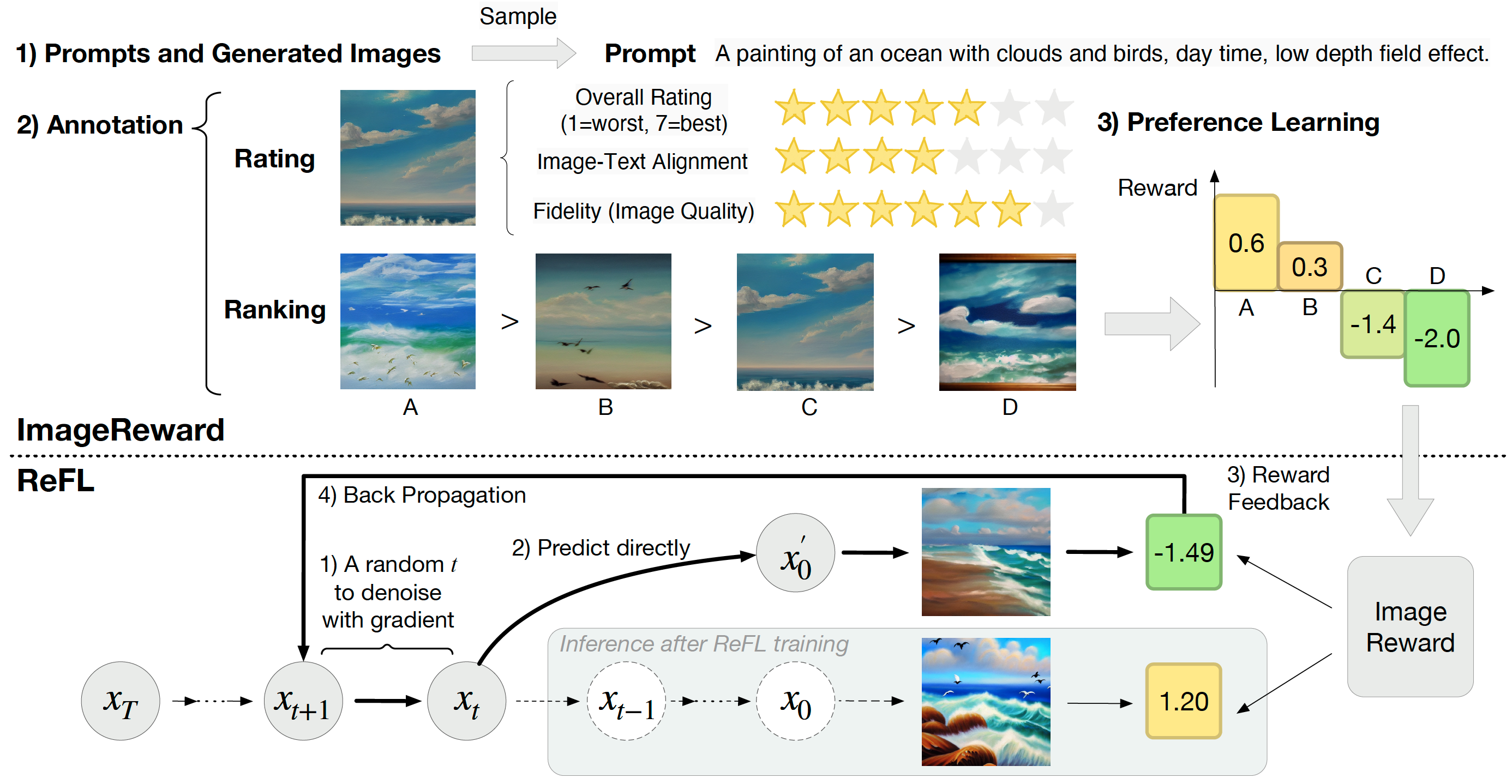
|
Project: HPS
Authors: Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Organizations: CUHK, SenseTime Research, Shanghai Jiao Tong University, Centre for Perceptual and Interactive Intelligence, Shanghai AI Lab
Summary: Fine-tune CLIP using annotated 98K SD generated images from 25K prompts for image generation evaluation.
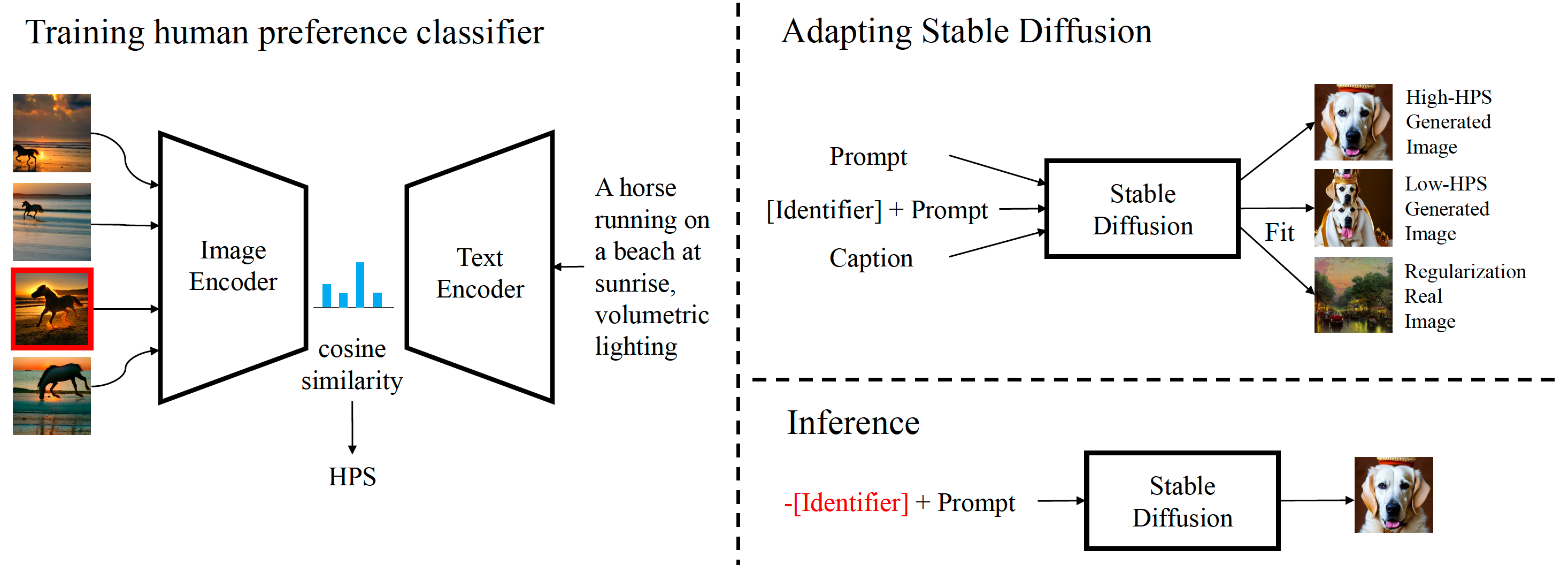
|
Project: DiT
Authors: William Peebles, Saining Xie
Organizations: UC Berkeley, New York University
Summary: Replace U-Net by transformer for scalable image generation, the timestep and prompt are injected by adaLN-Zero structure.
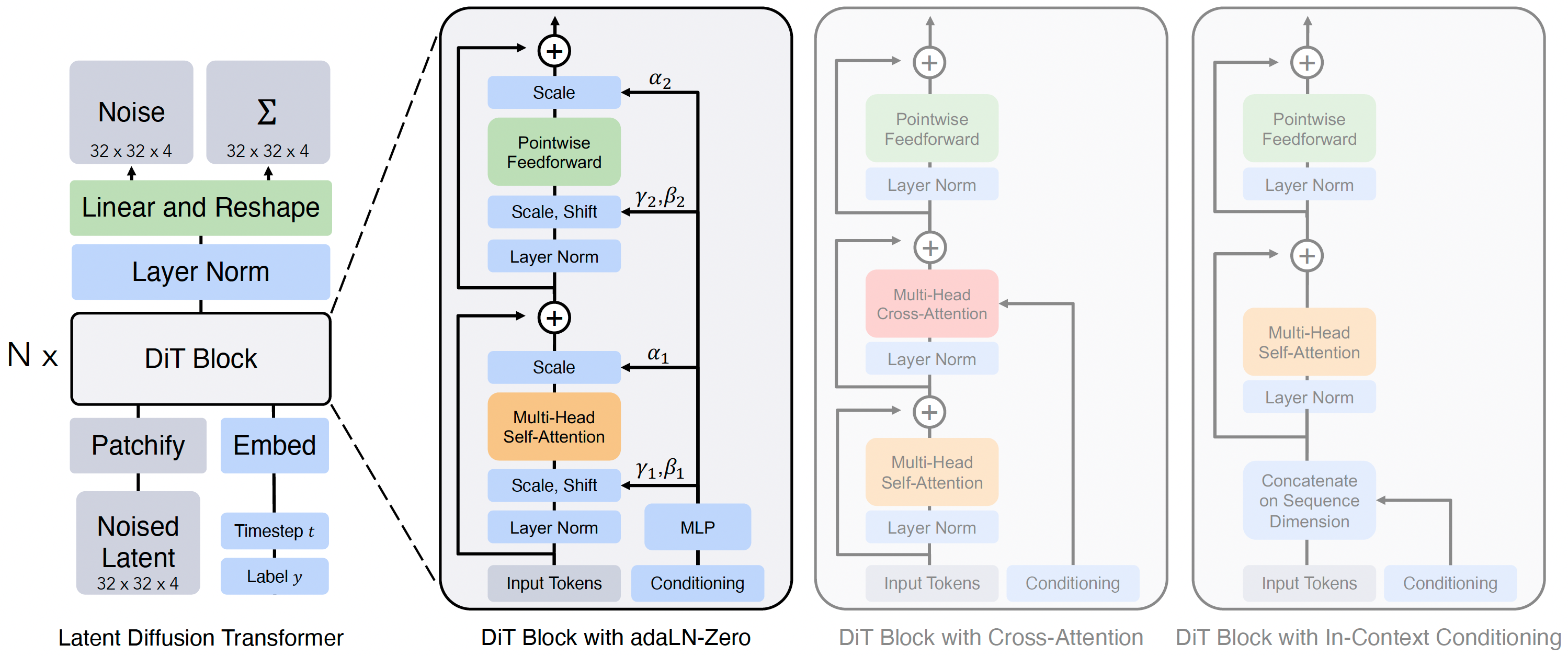
|
Project: promptist
Authors: Yaru Hao, Zewen Chi, Li Dong, Furu Wei
Organizations: Microsoft Research
Summary: Use LLM to refine prompts for preference-aligned image generation by taking relevance and aesthetics as reward.
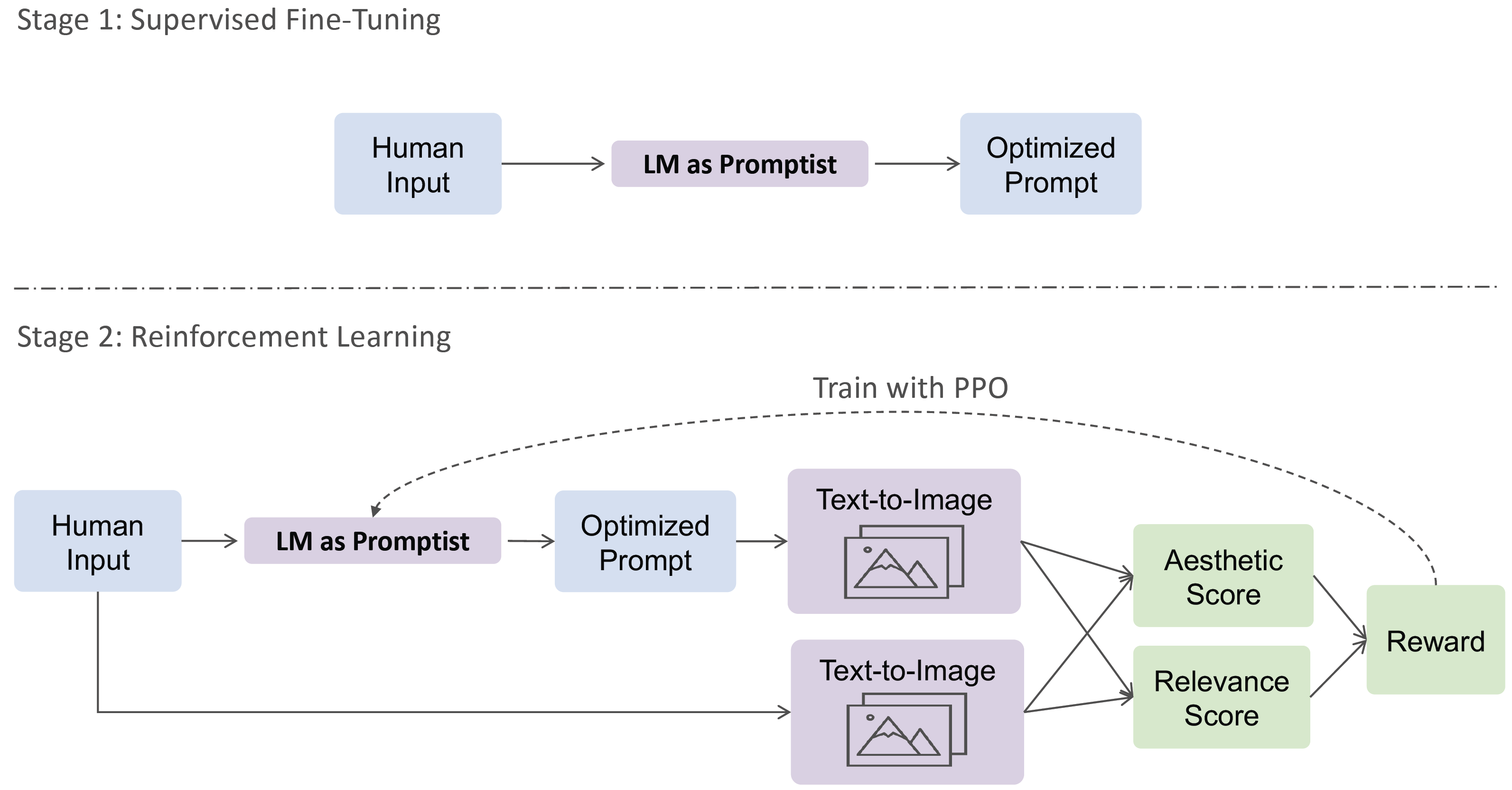
|
Project: Flow Matching
Authors: Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, Matt Le
Organizations: Meta AI (FAIR), Weizmann Institute of Science
Summary: A type of generative models built on continuous normalizing flows by learning a time-dependent vector field that transports data from the source distribution to the target distribution.
Project: Unified Perspective
Authors: Calvin Luo
Organizations: Google Brain
Summary: Introduction to VAE, DDPM, score-based generative model, guidance from a unified generative perspective.
Project: CogVideo
Authors: Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, Jie Tang
Organizations: Tsinghua University, BAAI
Summary: An open-sourced transformer-based video generation model (9B) that auto-regressively generates frame sequences and then performs auto-regressive frame interpolatation.
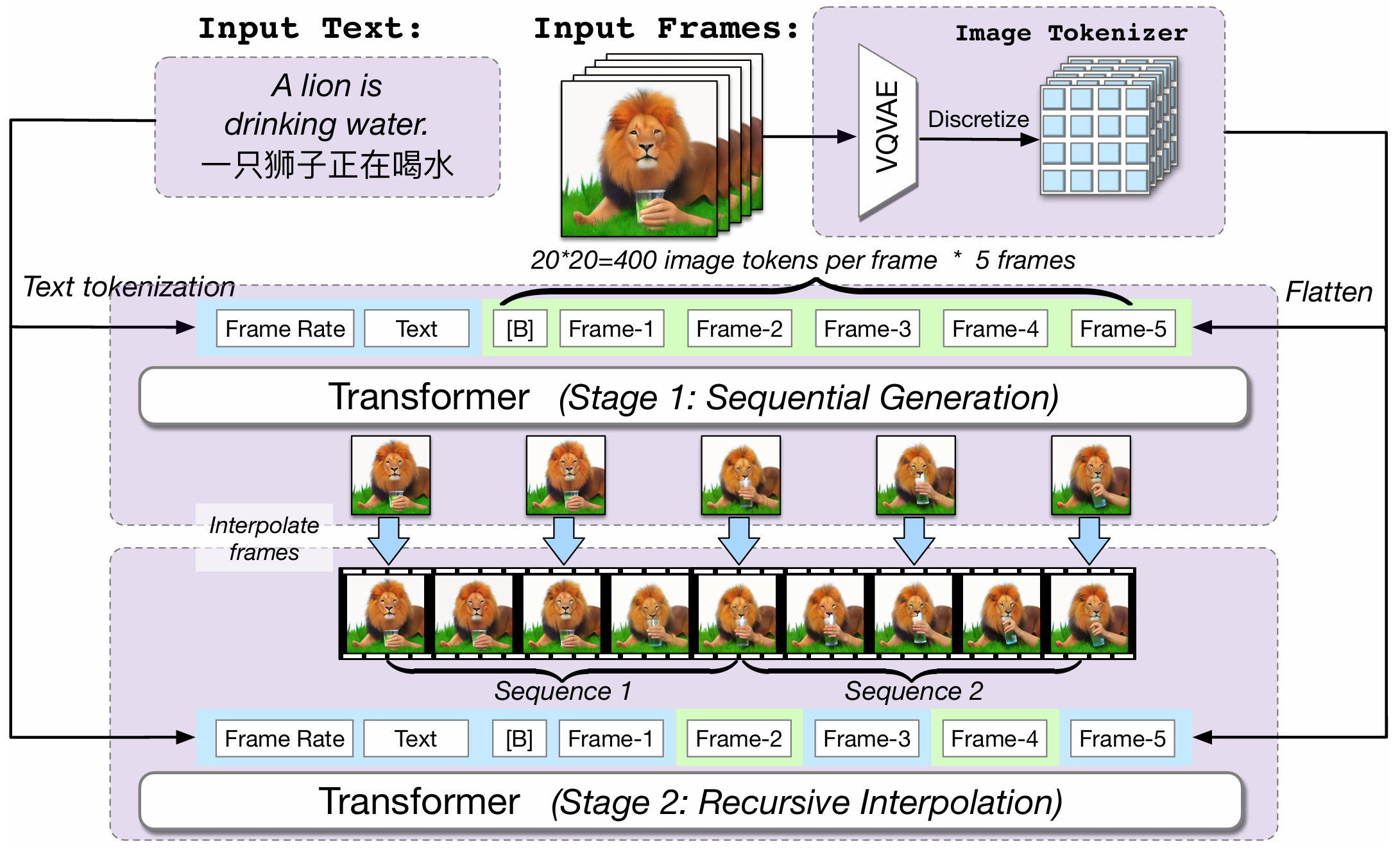
|
Project: LDM
Authors: Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Organizations: Heidelberg University, Runway ML
Summary: Efficient high-quality image generation by applying diffusion and denoising processes in the VAE latent space.
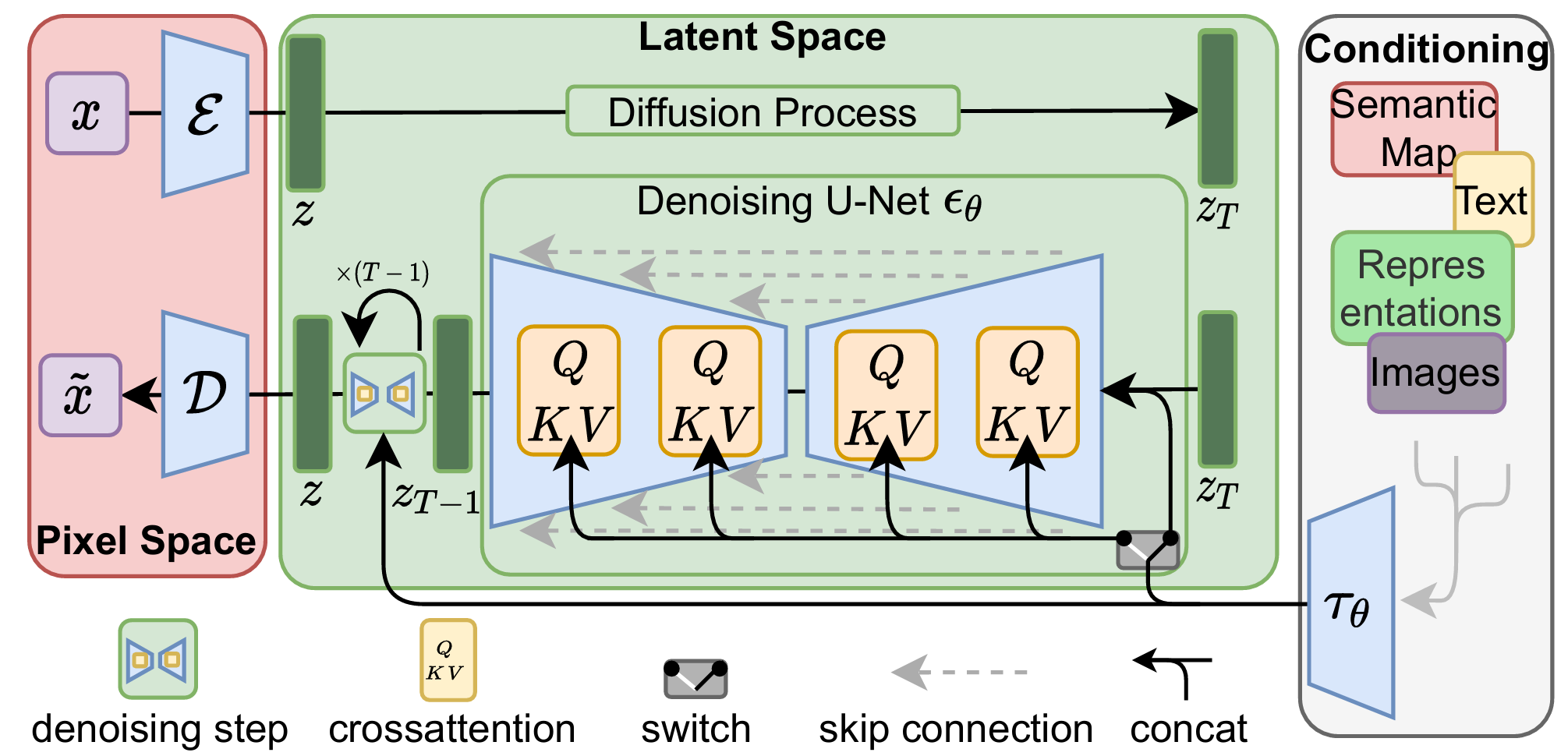
|
Project: CFG
Authors: Jonathan Ho, Tim Salimans
Organizations: Google Research, Brain team
Summary: Image generation with classifier-free condition guidance by jointly training a conditional model and an unconditional model.
Project: CLIPScore
Authors: Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, Yejin Choi
Organizations: Allen Institute for AI, University of Washington
Summary: A reference-free metric mainly focusing on semantic alignment for image generation evaluation.

|
Project: DDIM
Authors: Jiaming Song, Chenlin Meng, Stefano Ermon
Organizations: Stanford University
Summary: Accelerate sampling of diffusion models by introducing a non-Markovian, deterministic process that achieves high-quality results with fewer steps while preserving training consistency.

|
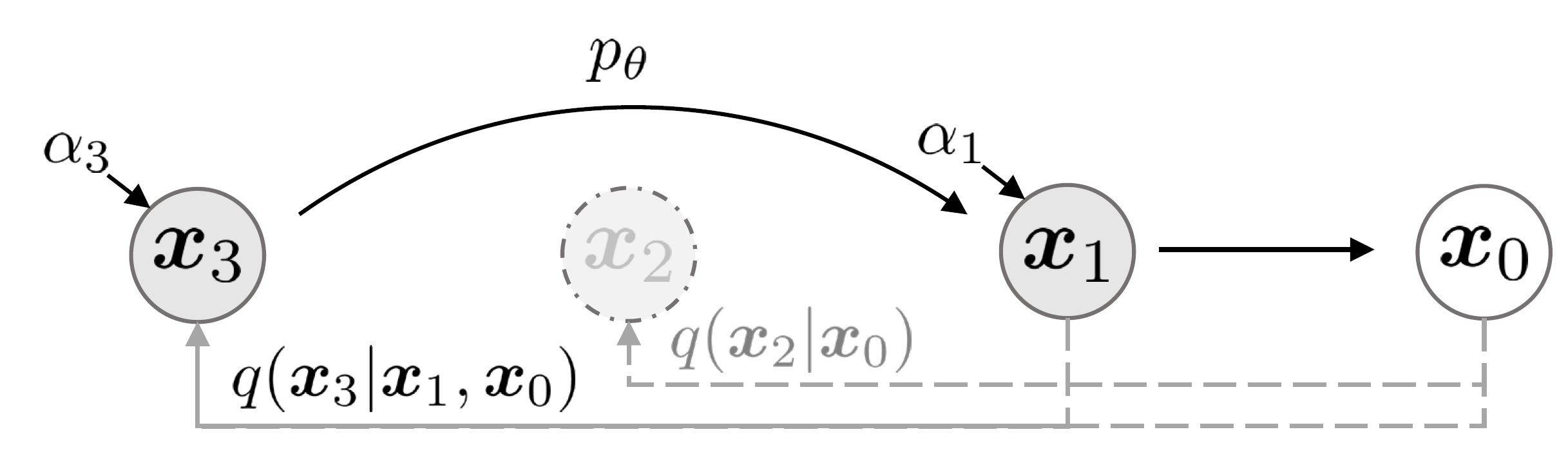
|
Project: DDPM
Authors: Jonathan Ho, Ajay Jain, Pieter Abbeel
Organizations: UC Berkeley
Summary: Denoising diffusion probabilistic models that iteratively denoises data from random noise for image generation.

|

|
Project: VQ-VAE-2
Authors: Ali Razavi, Aaron van den Oord, Oriol Vinyals
Organizations: DeepMind
Summary: Introduce hierarchical VQ-VAE and make sampling in the compressed latent space (which is faster than sampling in pixel space), inspired by the idea of lossy compression.

|
Project: FVD
Authors: Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, Sylvain Gelly
Organizations: Johannes Kepler University, IDSIA, Google Brain
Summary: Extend FID for video generation evaluation by replacing 2D InceptionNet with pre-trained Inflated 3D convnet.
Project: VQ-VAE
Authors: Aaron van den Oord, Oriol Vinyals, Koray Kavukcuoglu
Organizations: DeepMind
Summary: Propose vector quantised variational autoencoder to generate discrete codes while the prior is also learned.
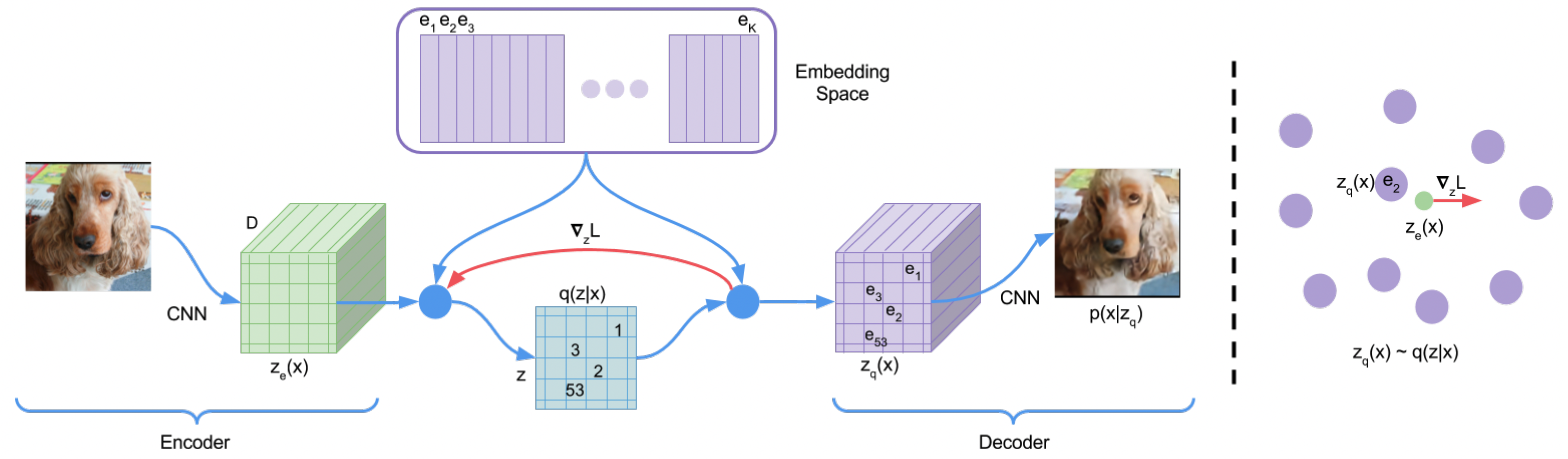
|
Project: FID
Authors: Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, Sepp Hochreiter
Organizations: Johannes Kepler University Linz
Summary: Calculate Fréchet distance between Gaussian distributions of InceptionNet feature maps of real-world data and synthetic data for image generation evaluation.
Project: Inception Score
Authors: Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen
Organizations: OpenAI
Summary: Calculate KL divergence between p(y|x) and p(y) that aims to minimize the entropy across samples and maximize the entropy across classes for image generation evaluation.