UniFluid
Show-o

Chameleon
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-04-08 GPT-4o Empirical Study |
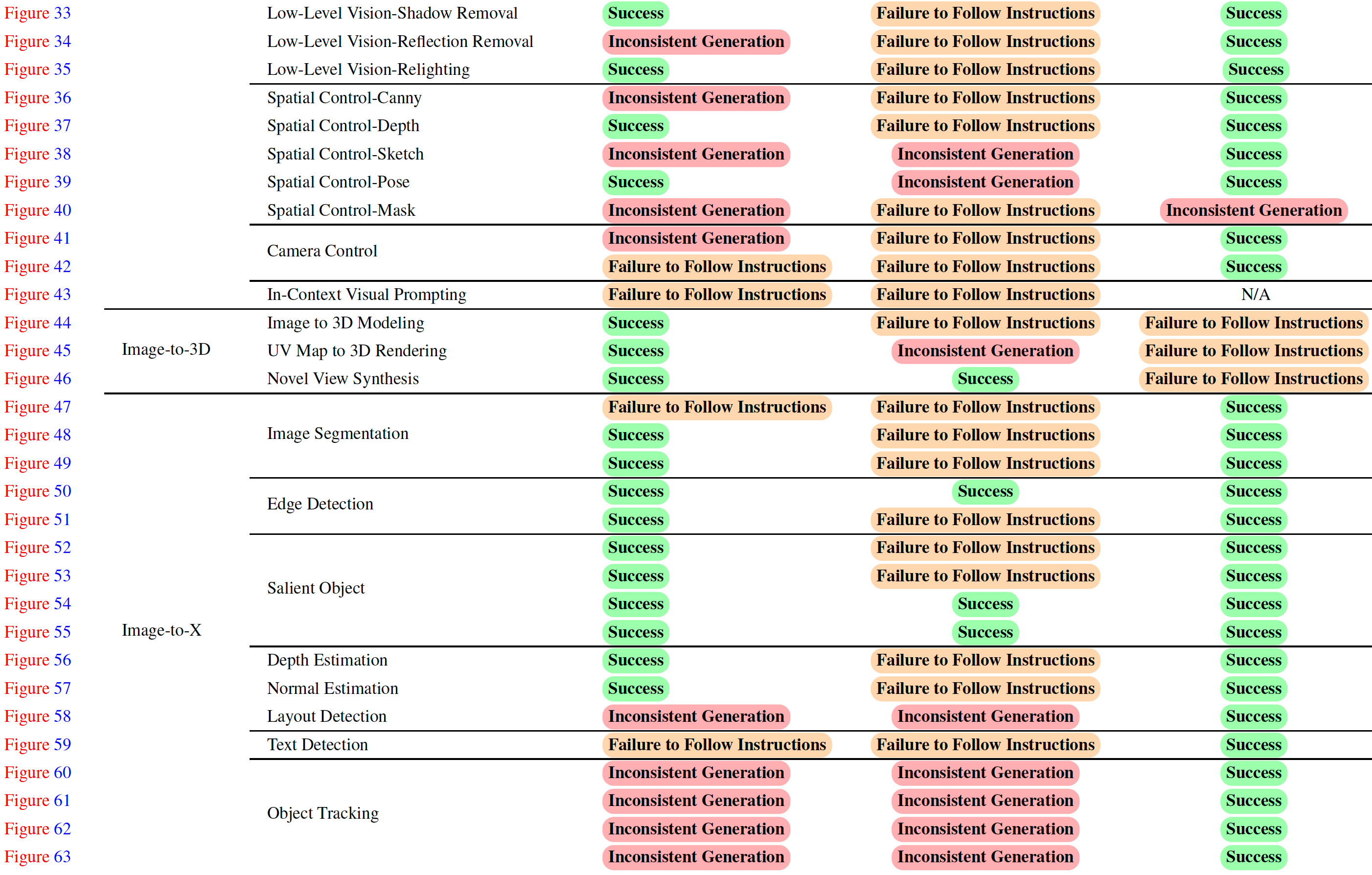
An Empirical Study of GPT-4o Image Generation Capabilities (arXiv 2025) | Empirical study of GPT-4o's image generation capability on text-to-image, image-to-image, image-to-3D, and image-to-X. |
| Date & Model | Paper & Publication & Project | Summary |
|---|---|---|
| 2025-03-17 UniFluid |
Unified Autoregressive Visual Generation and Understanding with Continuous Tokens (arXiv 2025) | An autoregressive framework for joint visual generation and understanding, using continuous visual tokens. |
| 2024-08-22 Show-o |
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation (ICLR 2025)
|
A transformer to unify multimodal understanding and generation, supporting VQA, text-to-image generation, text-guided inpainting/extrapolation, mixed-modality generation. |
| 2024-05-16 Chameleon |
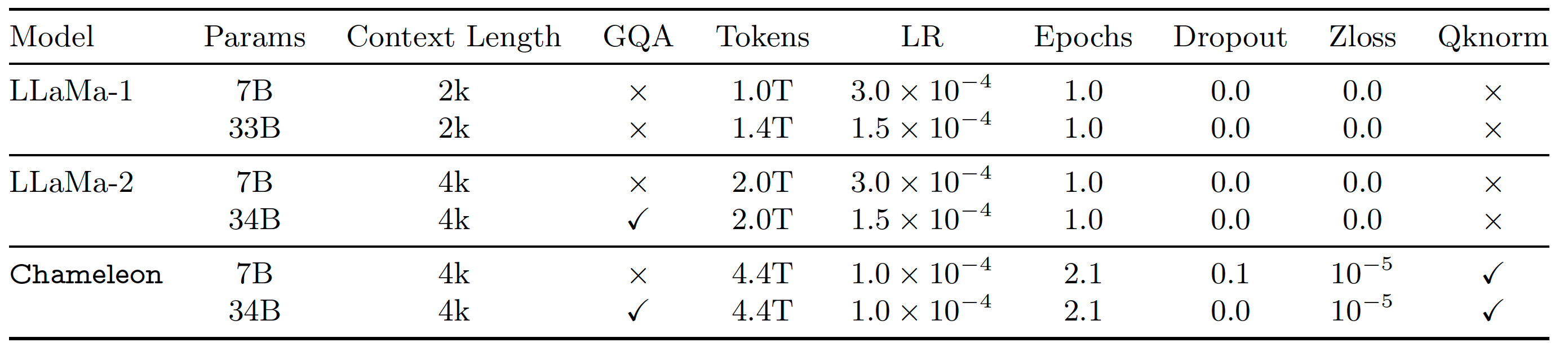
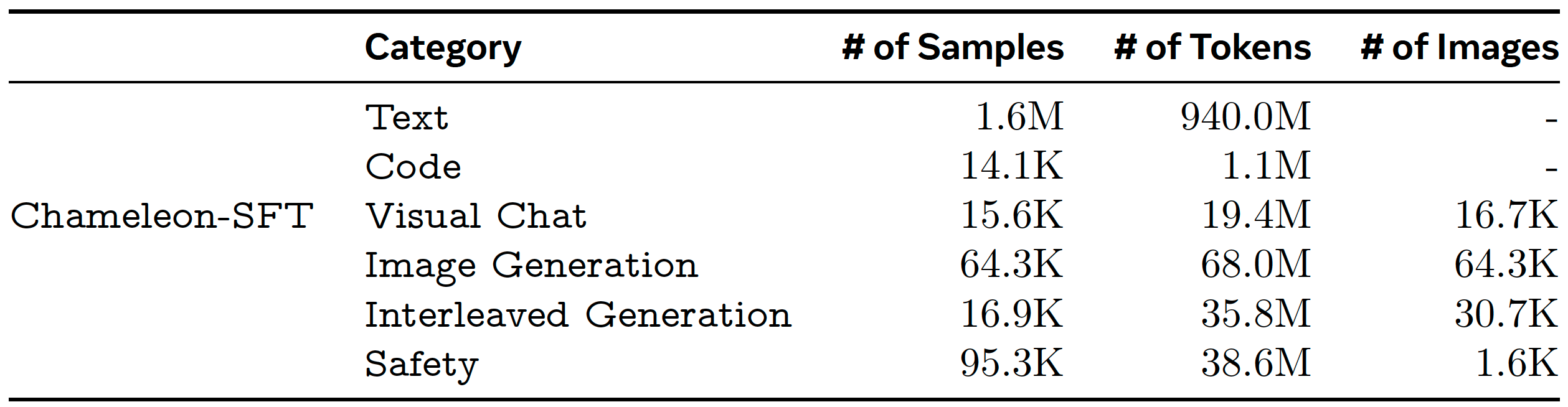
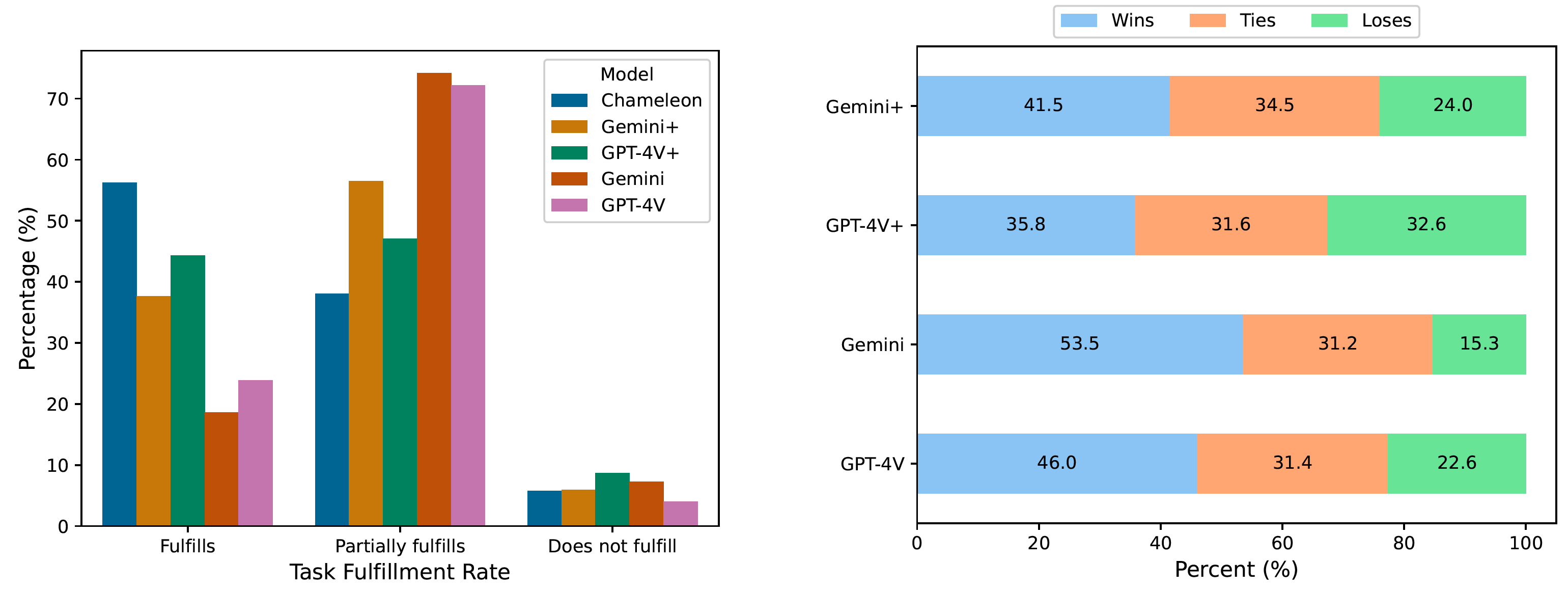
Chameleon: Mixed-Modal Early-Fusion Foundation Models (arXiv 2024) | Early-fusion token-based mixed-modal model (34B) trained on 10T interleaved mixed-modal data for understanding & generation of text & images. |
Authors: Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, Shilin Xu, Tao Zhang, Haobo Yuan, Yikang Zhou, Wei Chow, Linfeng Li, Xiangtai Li, Lei Zhu, Lu Qi
Organizations: The Hong Kong University of Science and Technology (GZ), National University of Singapore, Peking University, The Chinese University of Hong Kong, University of Washington, Wuhan University
Summary: Empirical study of GPT-4o's image generation capability on text-to-image, image-to-image, image-to-3D, and image-to-X.

|
|
Authors: Lijie Fan, Luming Tang, Siyang Qin, Tianhong Li, Xuan Yang, Siyuan Qiao, Andreas Steiner, Chen Sun, Yuanzhen Li, Tao Zhu, Michael Rubinstein, Michalis Raptis, Deqing Sun, Radu Soricut
Organizations: Google DeepMind, MIT
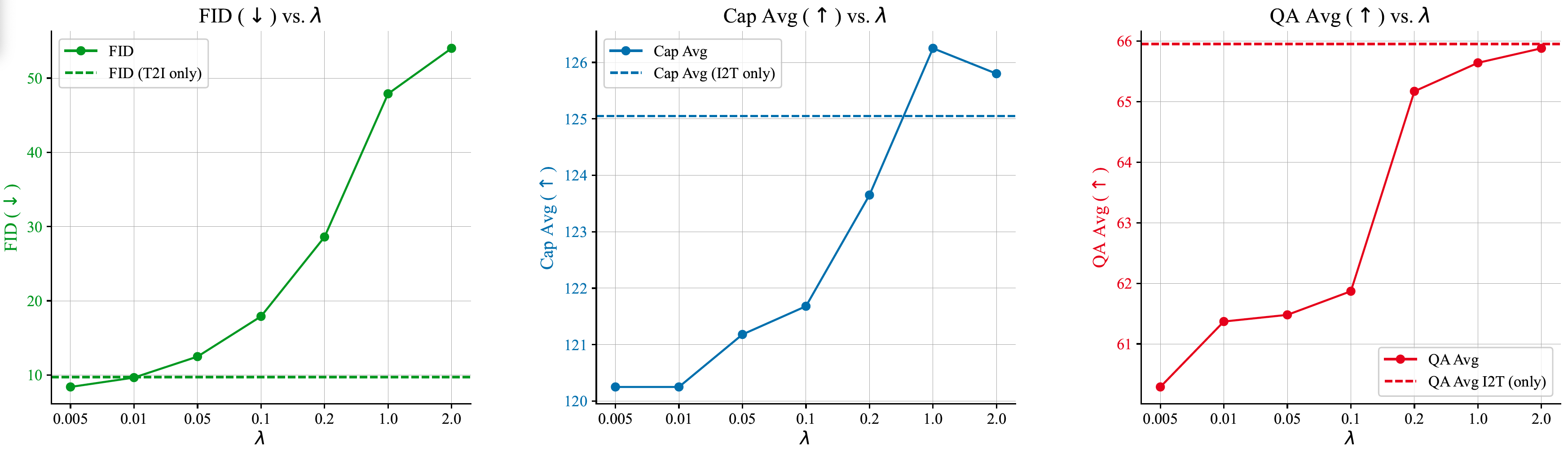
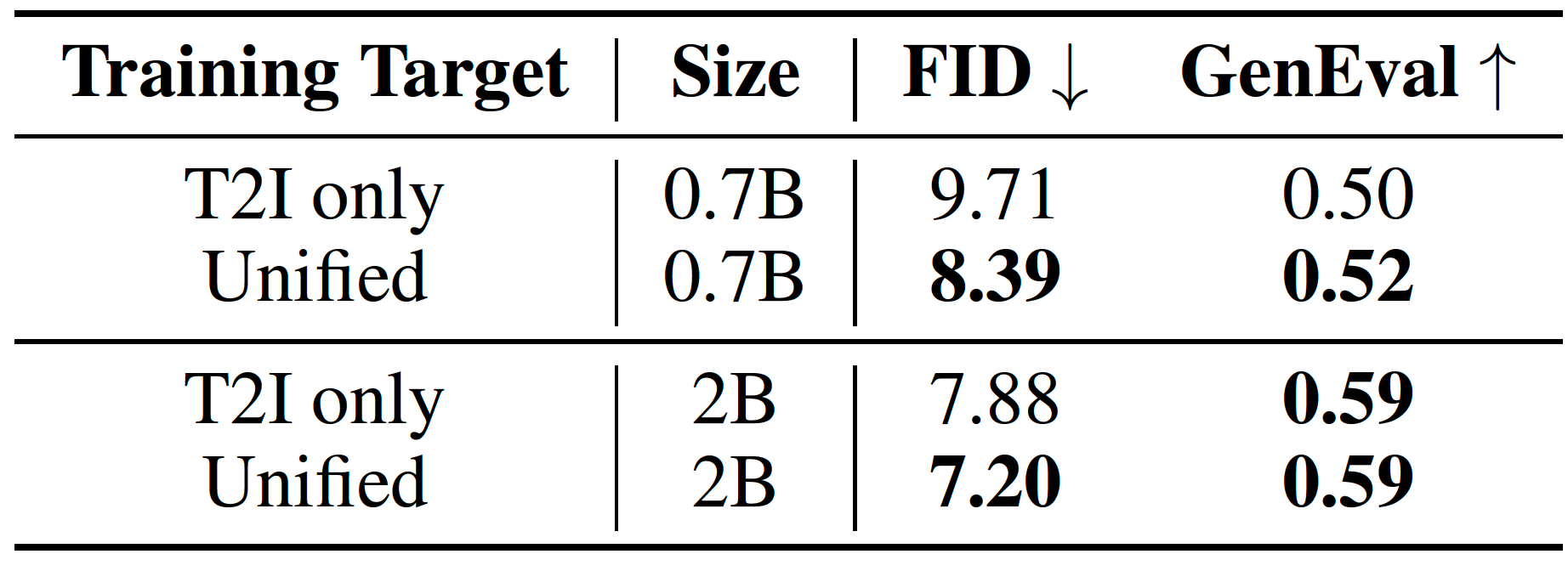
Summary: An autoregressive framework for joint visual generation and understanding, using continuous visual tokens.
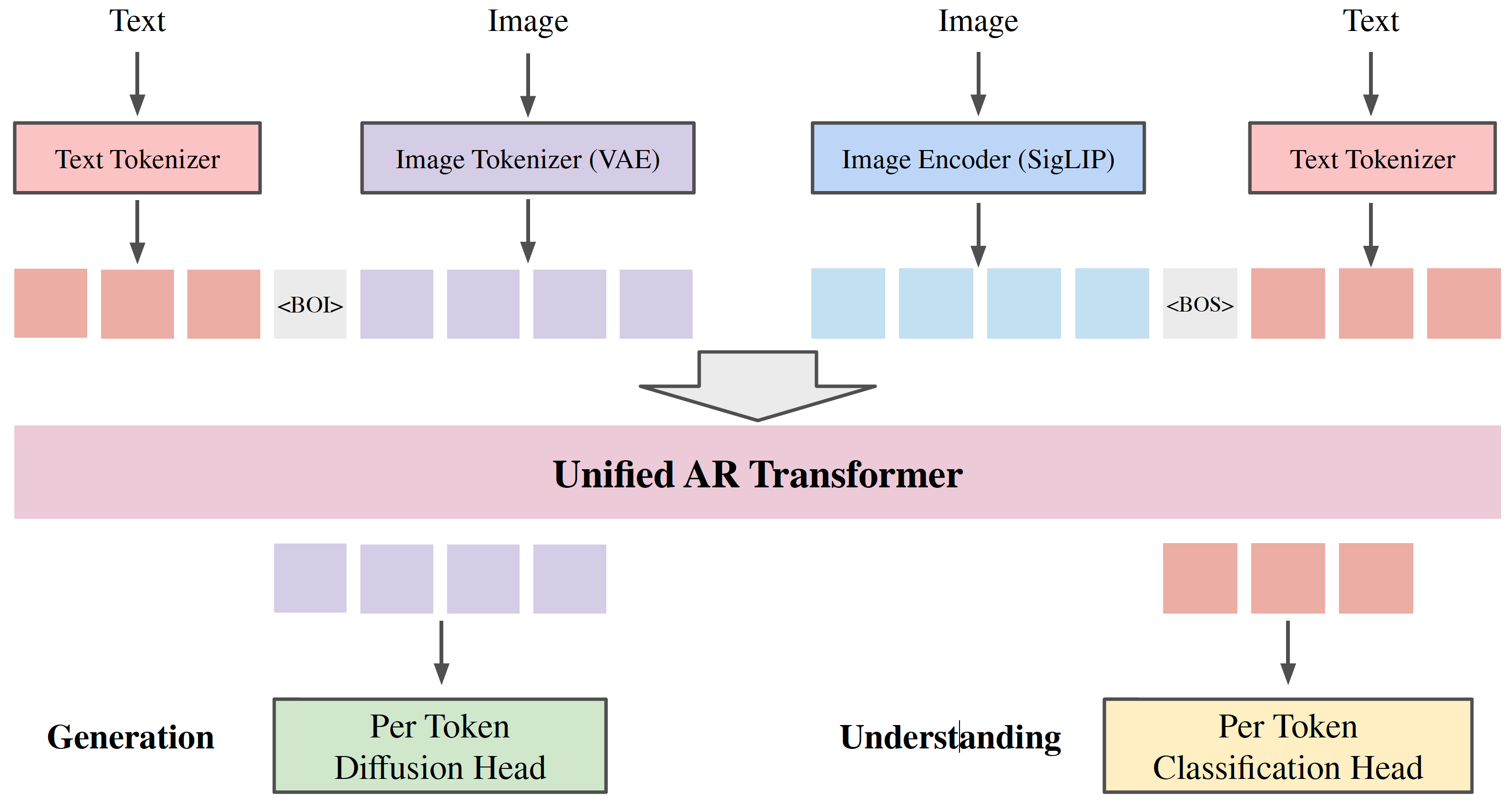
Tokenizer: use VAE image tokenizer for generation, SigLIP image encoder for understanding, SentencePiece tokenizer for text. Prediction head: use modality-specific prediction heads to calculate losses and sampling for each modality. Token split: "Beginning of Image (BOI)" token to indicate continuous image tokens. Loss: loss1: image understanding loss on text answer; loss 2: image generation loss on image tokens. Training details: batchsize=2048, optimizer=AdamW, lr=1e-4, steps=1M, init_ckpt=Gemma-2. |
|
|
|
|

|
Authors: Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou
Organizations: National University of Singapore, ByteDance
Summary: A transformer to unify multimodal understanding and generation, supporting VQA, text-to-image generation, text-guided inpainting/extrapolation, mixed-modality generation.

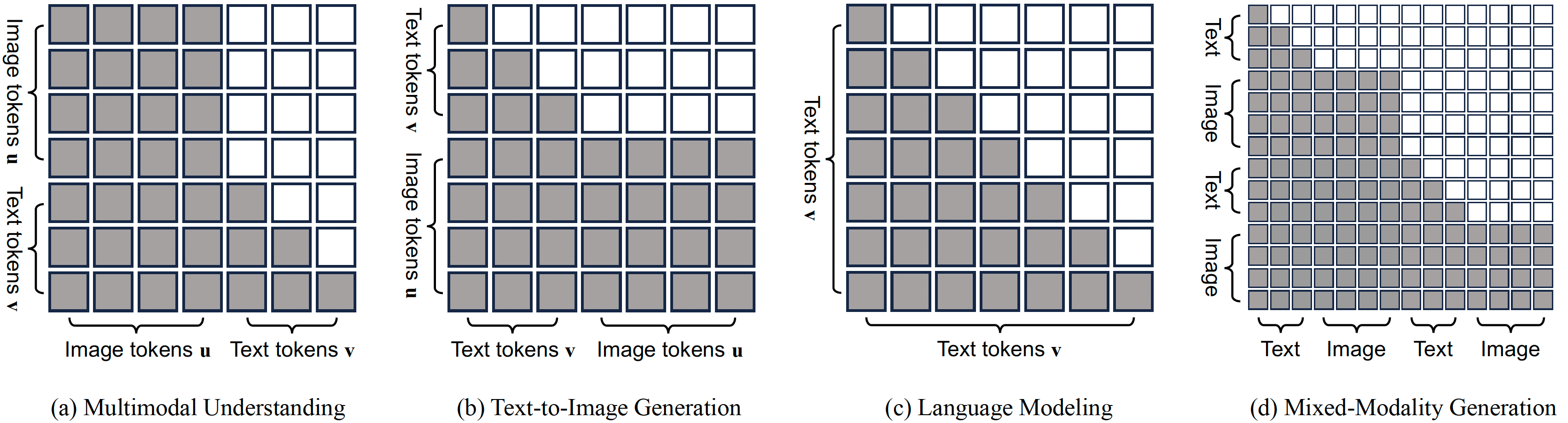
SD3: input continuous language; use diffusion; output continous vision LlamaGen: input discrete language; use LLM; output discrete vision NExT-GPT, SEED-X: input discrete language & continuous vision; use LLM & diffusion; output discrete language & continuous vision LWM, Chameleon: input discrete language & discrete vision; use LLM; output discrete language & discrete vision Show-o: intput discrete language & discrete vision; use LLM + diffusion; output discrete language & discrete vision |
|
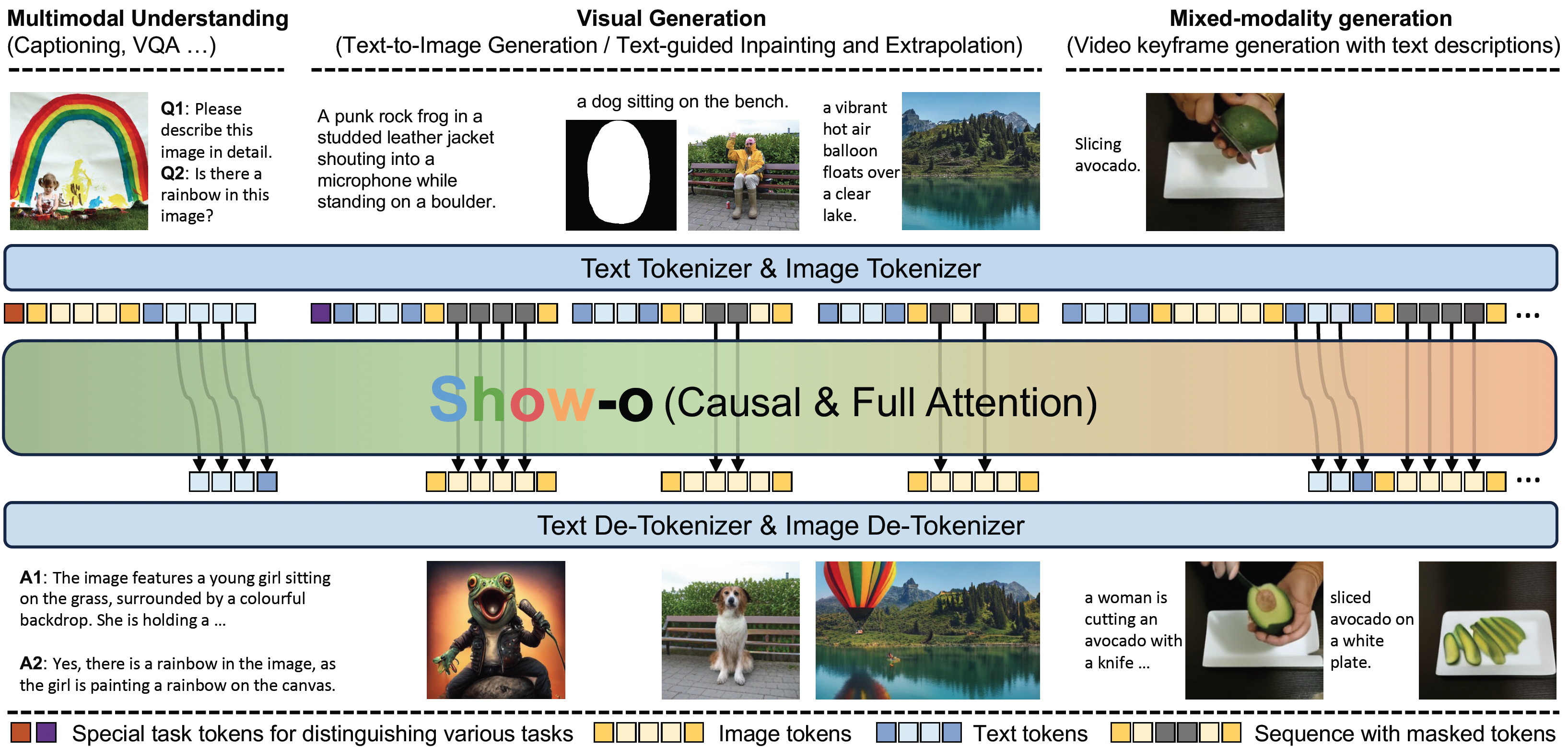
Tokenizer: do not change text tokenizer; employ discrete image tokenizer. Training objective: next-token prediction for text; masked token prediction for images. Training stages: (1) use RefinedWeb & ImageNet-1K to learn class-conditional image generation and image captioning; (2) use image-text data CC12M, SA1B, LAION-aesthetics-12M, DataComp, COYO700M to learn t2i generation; (3) use high-quality / instructional data LLaVA-Pretrain-558K, LLaVA-v1.5-mix-665K, GenHowTo to learn t2i generation & multimodal understanding & mixed-modality generation. |
|

|
|
|
Authors: Chameleon Team
Organizations: FAIR at Meta
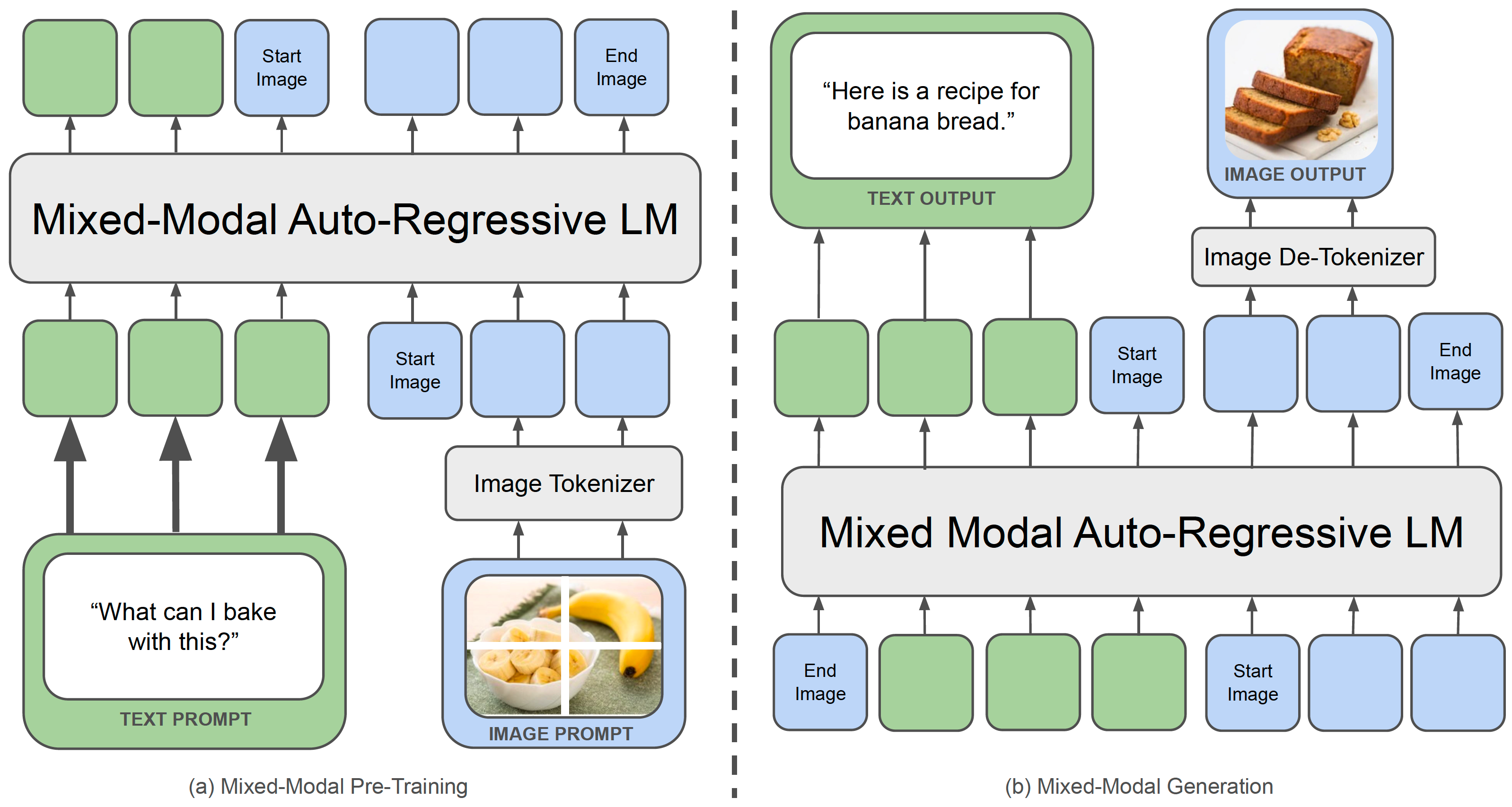
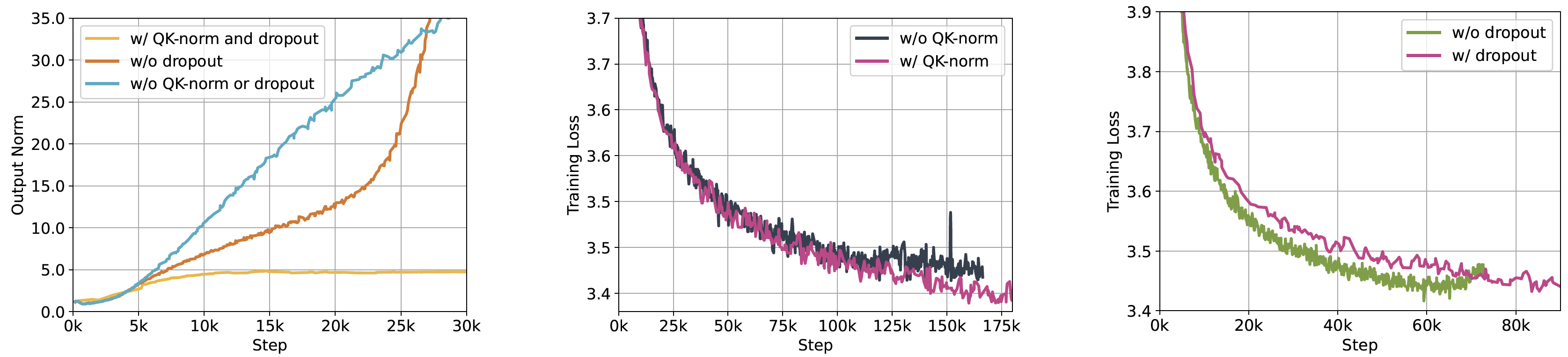
Summary: Early-fusion token-based mixed-modal model (34B) trained on 10T interleaved mixed-modal data for understanding & generation of text & images.
|
|
|
|
|